
[CS231n]Lecture 6-Training Neural Networks, Part 1 - 3rd
30 Jul 2021 | CS231n
지난 포스트와 이어지는 내용입니다. Batch Normalization, babysitting the learning process 그리고 hyperparameter optimization에 대해 다룹니다.
Batch Normalization
딥러닝의 고질적인 문제인 gradient explode/vanishing은 layer가 많아지면서 초기의 작은 변화가 많은 layer를 거치면서 누적되기 때문에 발생한다. 이는 학습 효율 저하 혹은 학습 실패를 야기하므로 반드시 해결해야 한다. 적절한 activation function과 weight initialization의 선택은 이 문제를 해결하기 위한 방법이었다. 한 가지 예로, sigmoid 활성화 함수를 사용하면 saturation이 발생하므로 ReLU라는 새로운 함수가 등장했다. 또한, 효율적인 학습을 위해 Xavier나 He 초기화를 사용하기도 했다. 하지만 layer가 일정 수 이상으로 많아지면 여전히 성공적으로 학습하지 못 하는 경우가 발생했다. Batch normalization은 앞선 방법들처럼 간접적인 방법이 아닌 학습 과정 자체를 안정화함으로써 본질적으로 문제를 해결하고자 제안되었다.
Internal Covariance Shift
We define Internal Covariate Shift as the change in the distribution of network activations due to the change in network parameters during training.
Batch normalization을 소개한 Ioffe & Szegedy는 학습 불안정의 원인이 internal covariance shift라고 설명한다. Internal covariance shift란 layer를 통과할 때마다 입력값의 분포가 변하는 것으로 이전 layer의 파라미터가 계속 update 되기 때문에 발생한다. 결국 학습이 반복될수록 뒤쪽 layer의 분포가 심하게 변하면서 학습이 잘 되지 않게 된다.
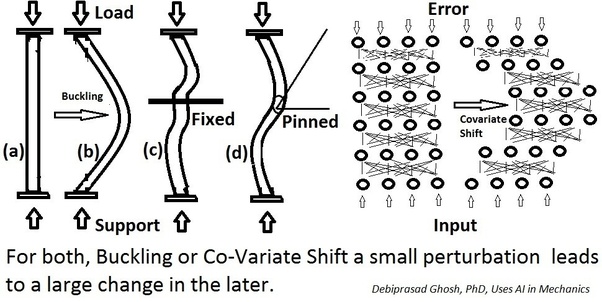 출처 : Debiprasad Ghosh
출처 : Debiprasad Ghosh
Internal covariance shift를 해결하기 위한 방법으로 whitening을 생각할 수 있다. Whitening은 입력값의 feature들이 uncorrelated이고 각각 분산 1을 가지게 만드는 과정이다. 하지만 이는 계산량이 많으며, 일부 파라미터가 무시될 수 있다는 문제가 있다. 입력값의 분산이 $\Sigma$라고 했을때 분산을 identity matrix로 만들기 위해 $\Sigma^{-1/2}$의 연산이 필요한데 이것은 많은 계산량을 요구한다. 또한, 입력값을 $u$, 출력값을 $x=u+b$ ($b$는 학습된 파라미터)로 하는 layer가 있다고 했을때, 평균을 빼는 과정 $x - E(x)$를 거치면 출력값에 $b$의 영향이 제거되고, 이는 결국 학습에 악영향을 준다. 표준화까지 하면 그 영향은 더 커진다고 한다. 때때로 미분불가능한 것도 whitening의 문제 중 하나이다.
Algorithm
Whitening의 문제를 보완하고, internal covariance shift를 해결하기 위해 논문에서는 다음의 알고리즘을 제시하였다.

많은 경우 mini-batch SGD 방법을 사용하므로, 비효율적인 입력값 전체의 full whitening보다는 batch의 feature별 정규화를 실시한다. 여기서 평균과 분산은 전체 training set에서 계산된다.
\[\hat{x}^{(k)} = \frac{x^{(k)} - E(x^{(k)})}{\sqrt{Var(x^{(k)})}}\]
이러한 정규화는 feature들이 decorrelated되지 않더라도 수렴 속도를 가속화한다고 알려져 있다. 하지만, -1과 1 사이의 값을 가지게 만들기 때문에 특정 활성화 함수를 사용하면 비선형 함수를 선형 함수처럼 만들어 버릴 위험이 있다.
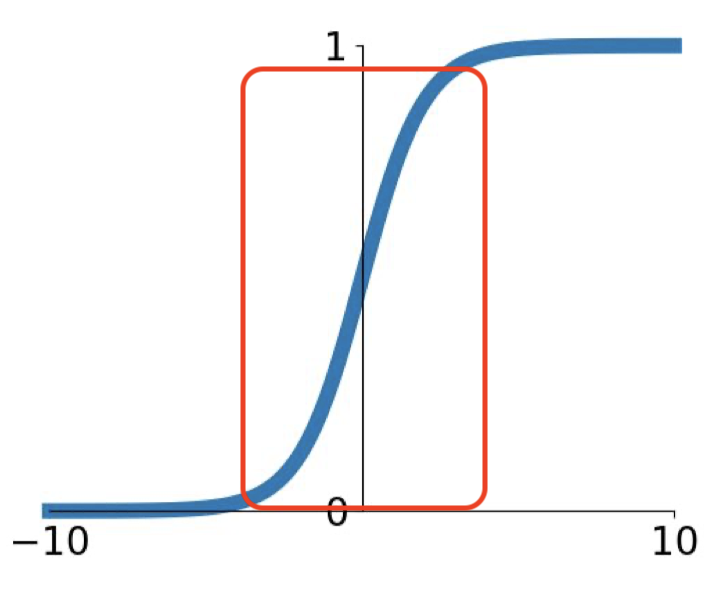 [-1,1] 범위로 제한되면 선형 함수와 비슷해진다.
[-1,1] 범위로 제한되면 선형 함수와 비슷해진다.
이를 방지하기 위해 학습해야 하는 파라미터 $\gamma$ (scale factor)와 $\beta$ (shift factor)를 도입한다. 정규화된 $\hat{x}^{(k)}$에 이들을 추가한 $y^{(k)} = \gamma^{(k)} \hat{x}^{(k)} + \beta^{(k)}$를 출력값으로 활성화 함수에 건네준다. 경우에 따라 입력값을 그대로 출력값으로 내보내는 identity mapping도 가능하다. BN layer는 FC/convolutional layer 다음에, 활성화 함수 layer 전에 위치하여 별도로 평균과 분산을 바꾸는 것이 아닌 신경망 내에 존재한다는 것이 whitening과 구별되는 또다른 점이라고 할 수 있다.
BN 자체로 regularization 효과도 있어서 학습 속도를 느리게 하는 dropout를 제외할 수 있고, propagation에서 파라미터 scale의 영향을 받지 않으므로 learning rate를 크게 설정하여 속도를 빠르게 한다는 이점이 있다. Test나 convolutional layer를 사용할 경우, 다른 부분이 조금 있으니 논문을 통해 이를 확인하길 바란다.
Babysitting the Learning Process
처음부터 많은 양의 데이터를 전부 사용하기란 생각보다 쉽지 않다. 데이터의 양이 많아지면 학습 시간이 증가할텐데, 학습 중간에 오류를 발생하면 그것을 수정하는 데에 많은 시간과 노력이 필요하다. 이러한 번거로움을 피하기 위해 본격적인 학습에 앞서 적은 양의 데이터로 모의 학습을 해보자는 것이 이 절의 골자이다.
첫 번째 과정은 데이터 전처리이다. 적은 양의 데이터여도 전처리는 수행해야 한다. 이전 포스트에서 설명한 바가 있기 때문에 구체적으로 설명하지 않겠다. 한 가지만 덧붙이자면, 이미지 자료의 경우 값 자체가 의미를 지니고 있기 때문에 표준화를 하지 않는 경우가 많다. 두 번째 과정은 모델(혹은 신경망 구조)의 선택이다. 후보로 정한 여러 모델을 구체적으로 디자인하면 된다. Layer가 잘 구성되었는지 확인하기 위해 강의의 예시를 살펴보자.
 규제화 없이 softmax를 사용한 경우
규제화 없이 softmax를 사용한 경우
3장에서 softmax는 $-\log{x}$(밑은 자연상수 $e$이다)를 loss로 사용하는 것을 설명한 바가 있다. 예시의 경우, 10개의 클래스가 있으므로 규제를 하지 않았을 때 $\text{loss=} -\log{1/10} = 2.3$가 나와야 정상이다. 또한, 규제화 정도를 높이면 loss가 높아져야 한다. 이러한 점검 과정을 sanity check라고 하며 유사한 표현으로 double check, reality check 등이 있다.
 loss가 조금 증가한 결과
loss가 조금 증가한 결과
이제 적은 양의 데이터로 학습을 진행하자. 데이터의 양이 적기 때문에 train accuracy가 100%인 overfitting 상태가 되어야 한다. 적절한 learning rate(학습 속도)를 찾는 것도 중요하다. 너무 작게 설정하면 학습이 너무 오래 걸리고, 너무 크게 설정하면 loss가 수렴하지 않을 수 있다. 가운데 그림과 같이 초반에는 빠르게 학습을 하고 점점 속도를 줄여가는 것이 효율적이다. 규제화 정도와 학습 속도 모두 분석가에 의해 결정되는 hyperparameter이기 때문에 지금처럼 적은 데이터를 사용해 대략적인 범위로 제한한 뒤, cross validation(교차 검증)을 통해 최종 선택하는 것이 올바르다.
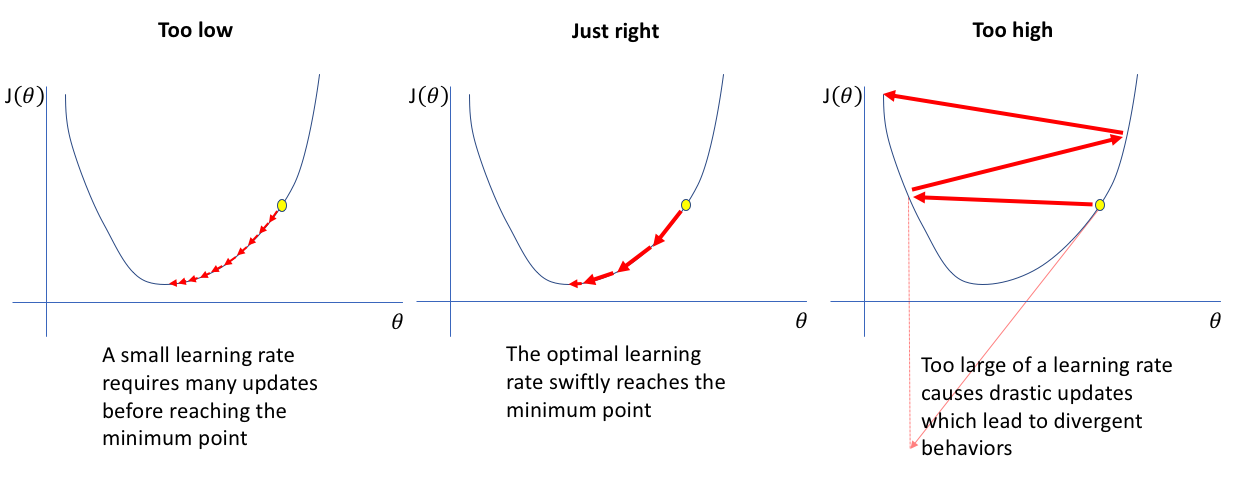 출처 : Jeremy Jordan
출처 : Jeremy Jordan
Hyperparameter Optimization
A model hyperparameter is a configuration that is external to the model and whose value cannot be estimated from data.
이번 절에서는 hyperparameter(초모수)를 결정하는 방법에 대해 알아볼 것이다. 초모수는 데이터로부터 추정할 수 없는 값으로 학습을 통해 추정하는 parameter(모수)와 구분된다. Learning rate 혹은 k-NN의 k 등이 초모수에 해당하며, 어떤 값을 취하느냐에 따라 학습의 결과가 매우 달라지기 때문에 적절한 초모수의 선택은 굉장히 중요하다.
Cross Validation
초모수를 결정하기 위해서는 cross validation(교차 검증)을 먼저 알아야 한다. 교차 검증은 초모수의 결정뿐만 아니라 모형간 성능 비교와 overfitting(과대적합) 혹은 underfitting(과소적합)을 피하기 위해 사용한다. 과적합과 관련해서는 3장에서 설명한 바 있다. 구체적인 과정을 살펴보도록 하자.
 교차 검증은 데이터를 분할하여 수행한다. (출처 : 고려대학교 통계적머신러닝 강의자료)
교차 검증은 데이터를 분할하여 수행한다. (출처 : 고려대학교 통계적머신러닝 강의자료)
먼저 전체 데이터를 training set, validation set, test set로 분할한다. 각 데이터 셋의 역할은 다음과 같다.
- Training set을 이용하여 모델의 모수를 추정한다.
- Validation set을 이용하여 초모수를 결정한다. Test set에 사용할 성능이 좋은 모델을 선택하는 것이다.
ex) 1-NN ~ 5-NN 중 어떤 모델이 성능이 좋은지 선택한다.
- Test data를 이용하여 최종 모델의 성능을 평가한다. 이것으로 모델간 성능을 비교할 수 있다.
ex) Random Forest vs. SVM
모든 데이터 셋은 한 번 사용하면 다시 사용하지 않는다. 같은 데이터로 학습하고 평가하면 성능이 잘못 평가되므로 조금만 생각해보면 당연하다. 하지만, 위와 같이 한 번만 분할해서 학습하면 우연히 좋거나 나쁜 validation set을 택하는 경우가 발생할 수 있다. 우리는 새로운 데이터에 대해서도 성능이 좋은 모델을 원하기 때문에 validation set에 대해 unbiased한 초모수를 결정해야 한다. 따라서 다음의 K-fold cross validation 방법을 사용한다. 데이터가 작아서 validation set을 나누기 어려울 때에는 LOOCV(Leave-one-out cross validation) 방법을 사용하기도 한다.
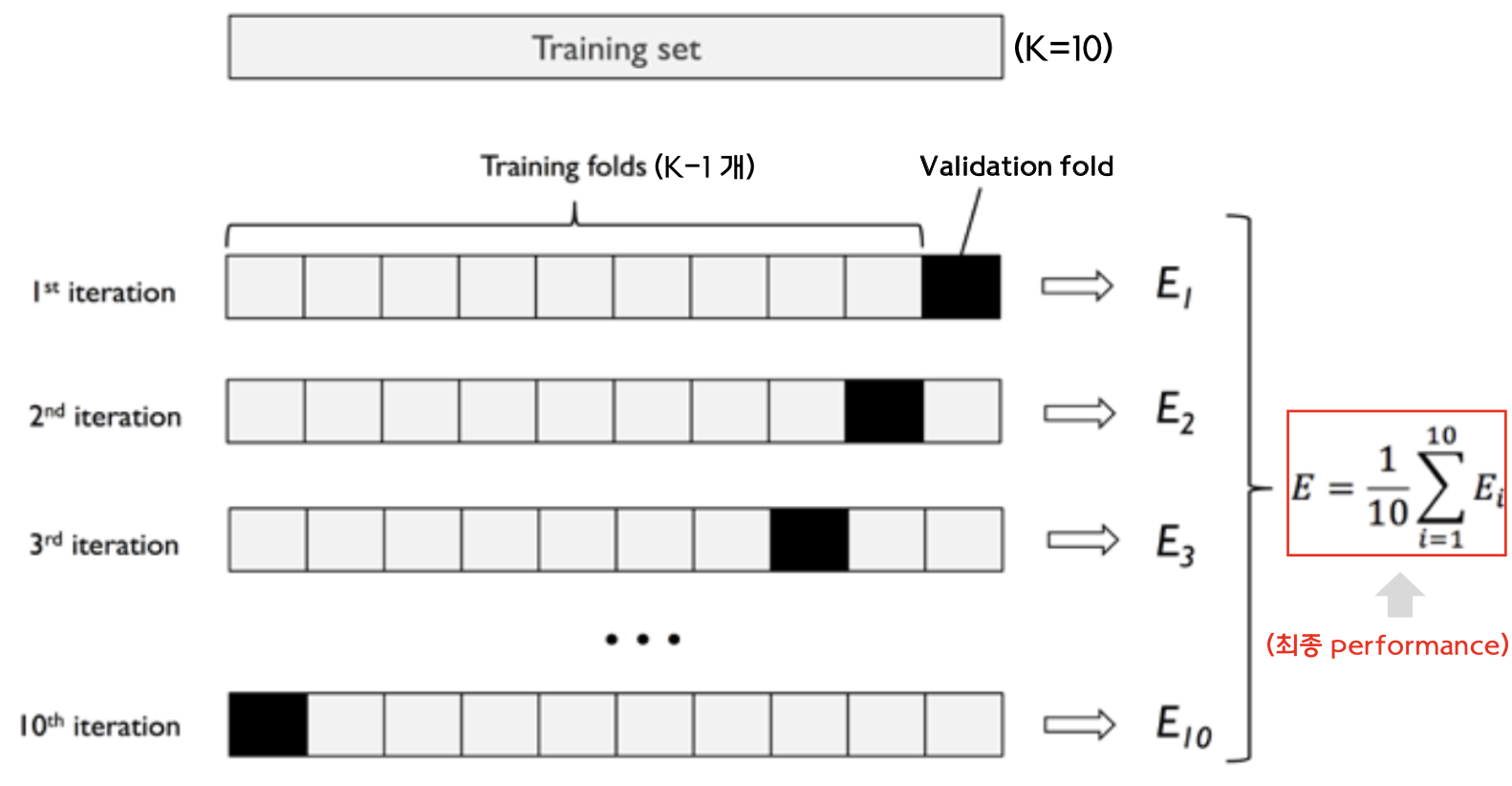 반복을 통해 초모수를 결정한다. (출처 : 고려대학교 통계적머신러닝 강의자료)
반복을 통해 초모수를 결정한다. (출처 : 고려대학교 통계적머신러닝 강의자료)
$E_i$는 $i$번째 반복에서의 모델 성능이며, 예시의 경우 training set을 10개로 분할했으므로($K=10$) 총 10개의 값을 얻는다. 가장 우수한 $E = \dfrac{1}{10} \sum_{i=1}^{10} E_i$를 보이는 초모수를 선택한다. Test set으로 선택된 모델을 평가하면 최종 성능을 얻을 수 있다. Validation set과 test set 모두 모델의 성능을 평가하므로 차이가 없다고 생각할 수 있는데 그렇지 않다. Validation set은 여러 모델 중 하나를 선택하는 학습 과정에만 관여하는 데이터이고, test set은 최종 모델의 성능을 평가하는 과정에만 관여한다.
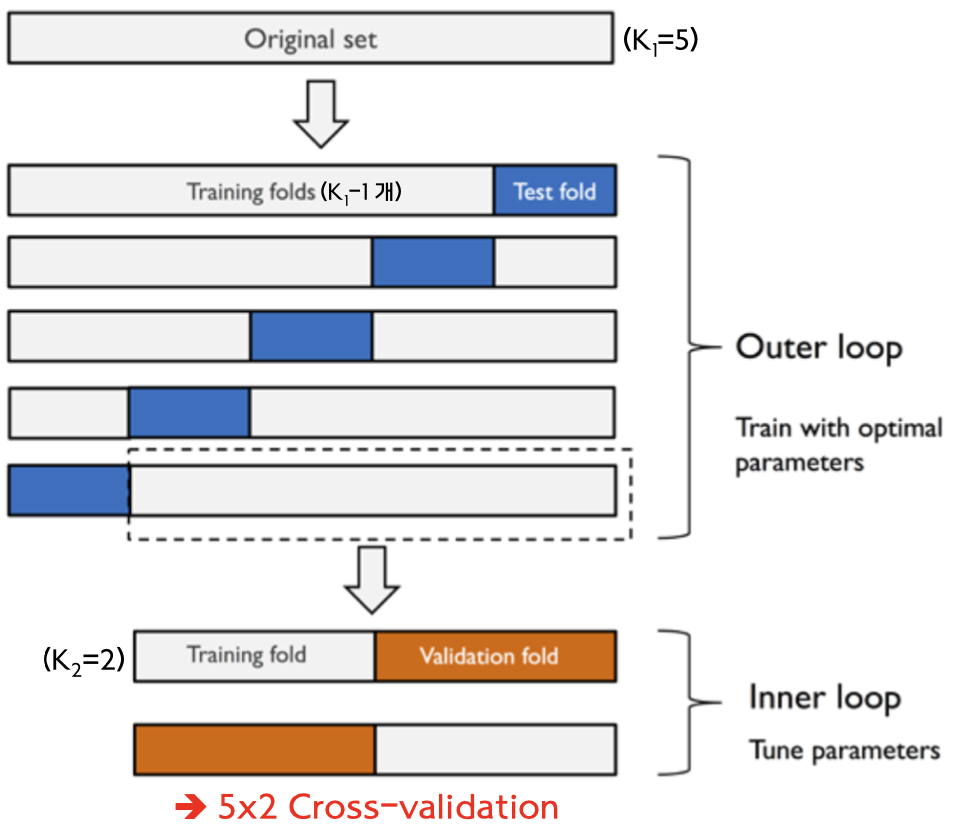 Nested Cross-Validation (출처 : 고려대학교 통계적머신러닝 강의자료)
Nested Cross-Validation (출처 : 고려대학교 통계적머신러닝 강의자료)
K-fold CV는 초모수가 validation set에 의존하는 문제를 해결하긴 했지만, test set에 대해서는 해결하지 못했다. 고정된 test set(고정된 자료 분할 방식)으로 인해 발생하는 문제를 해결하기 위해 nested cross validation 방법이 사용된다. 모델의 최종 성능은 여러 개의 test performance를 평균 내어 얻는다.
Hyperparameter Tuning
어떤 기준으로 초모수를 선택해야 하는 지는 살펴보았으니, 이번에는 어떤 초모수를 후보로 해야 하는지 알아보자. 대표적으로 두 가지 방법이 있는데 각각 grid search와 random search이다. Grid search의 경우 각 초모수의 후보를 사전에 결정해놓고 모든 경우의 수를 고려하는 방법이다. 그러나 실제 최적값이 1.5인데 우리의 후보에는 1과 2만 있다면 최적의 초모수를 선택할 수 없다. 이러한 단점을 보완하기 위해 고안된 것이 random search이다. Random search는 각 초모수의 범위를 설정한 뒤 그 범위에서 랜덤으로 추출하여 선택하는 방법이다. 최근에는 더 개선된 다양한 방법이 제안되고 있으니 최신 동향을 살펴보길 권장한다.
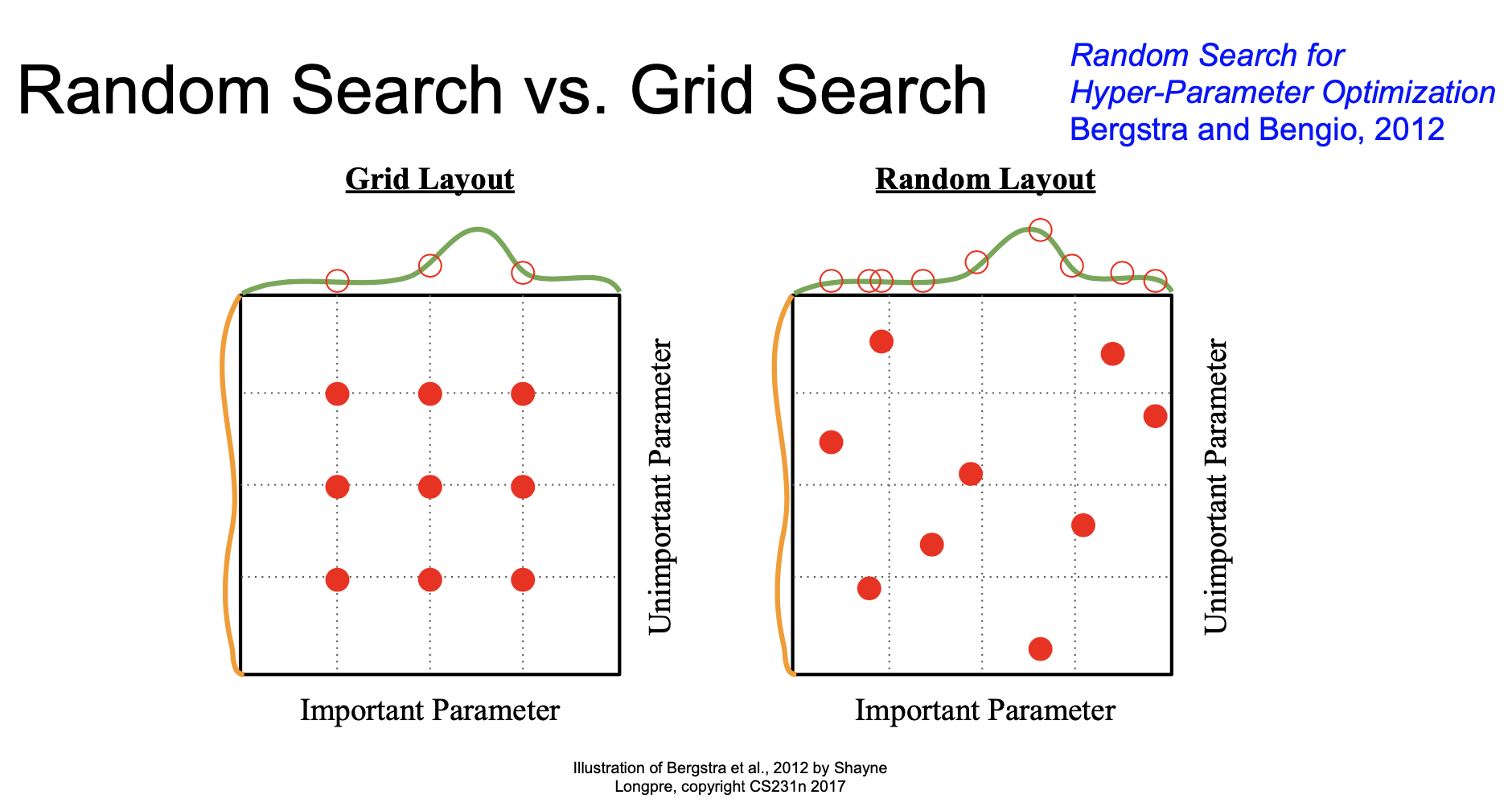 Grid Search and Random Search
Grid Search and Random Search
Loss curve와 train & test accuracy를 살펴보는 것도 좋은 방법이다. Loss curve를 시각화함으로써 learning rate가 너무 작거나 큰 지 확인할 수도 있으며, 초기화가 적절하게 되었는지 판단할 수 있다.
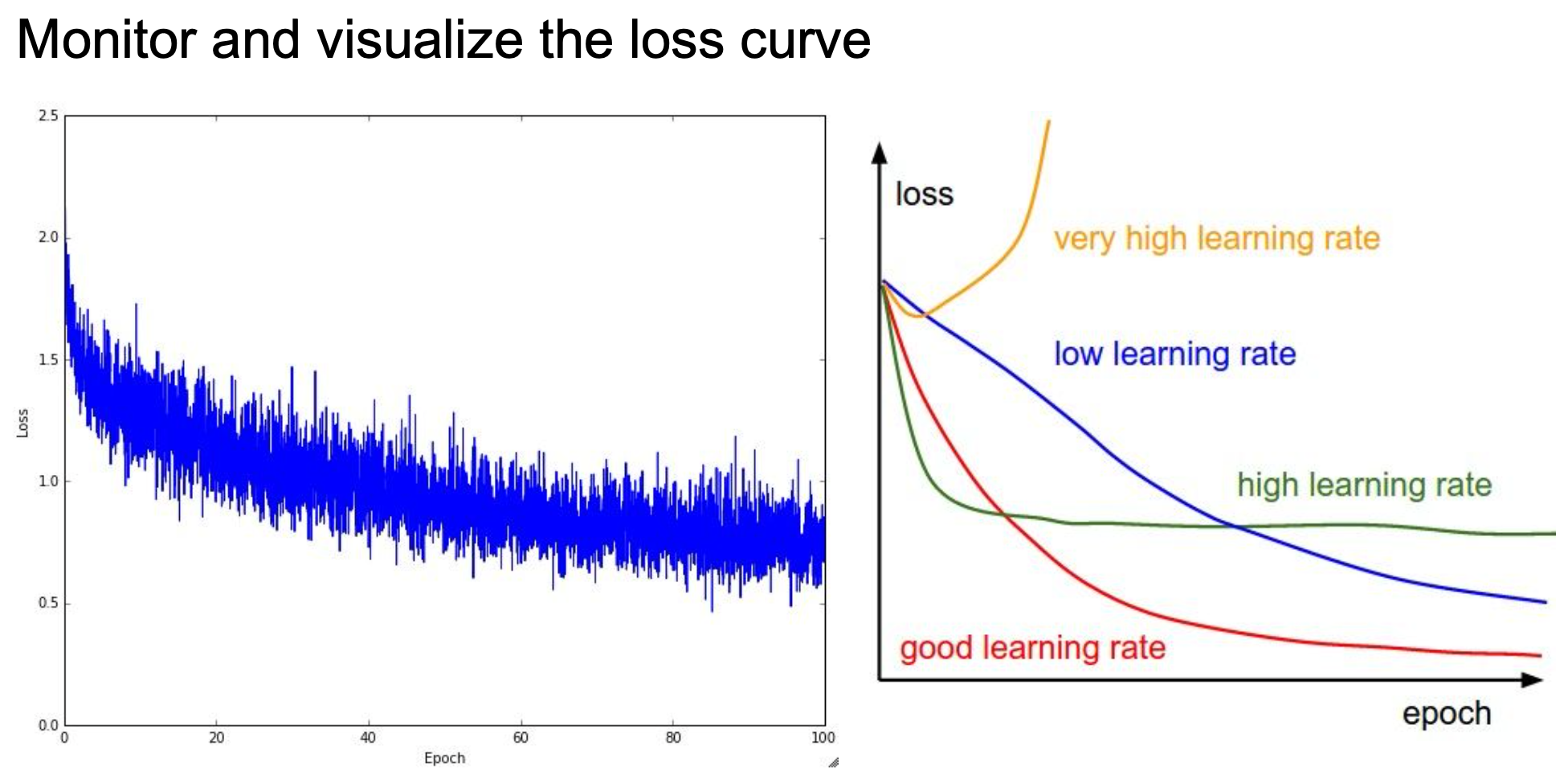 Loss curve를 시각화한 모습
Loss curve를 시각화한 모습
왼쪽 그림과 같이 loss가 좀처럼 줄어들지 않다가 갑자기 학습이 잘 진행된다면 다른 초기화 방법을 적용해서 학습 효율을 개선시킬 수 있다. 또한, train & test accuracy가 오른쪽 그림과 같은 양상을 보인다면 규제화 정도를 증가시키면 될 것이다. 이처럼 수치뿐만 아니라 시각화를 통해 효율적이고 직관적인 초모수 결정이 가능하다.
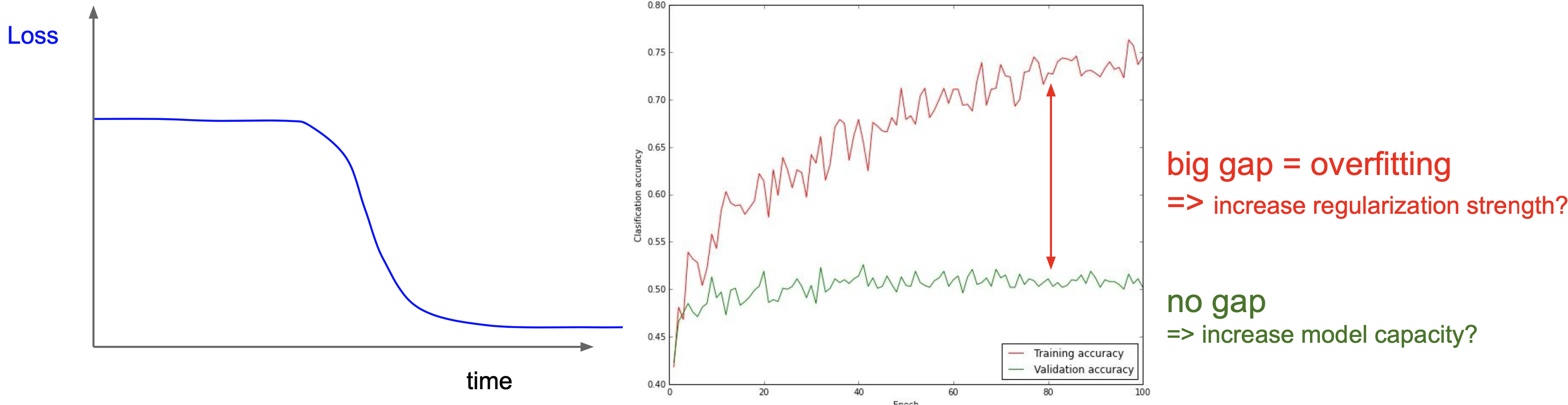 시각화를 통해 학습을 점검할 수 있다.
시각화를 통해 학습을 점검할 수 있다.
지금까지 모델 학습에 대한 전반적인 과정을 살펴보았다. 각 과정들이 분리된 것이 아니라 유기적으로 연결되어 있기 때문에 한 번 공부한다고 익힐 수 있는 내용들이 아니다. 또한 절대적인 규칙이 존재하지 않기 때문에 다양한 데이터를 분석해보고 시행착오를 겪으면서 경험을 습득하는 것이 무엇보다도 중요하다. 각자의 데이터와 분석 목적이 다를텐데 ‘이렇게 하면 성능이 좋다’는 말만 듣고 따라하기만 한다면 실력은 제자리 걸음만 할 뿐이다.
Further Reading
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Batch Normalization 설명 및 구현
- [Part IV. CNN 핵심 요소 기술
] 1. Batch Normalization [1] -라온피플 머신러닝 아카데미-
- [Deep Learning] Batch Normalization 개념 정리
- Why does batch normalization help?
- Setting the learning rate of your neural network.
- What is the Difference Between a Parameter and a Hyperparameter?
- 3.1. Cross-validation: evaluating estimator performance
- 박유성. “통계적머신러닝” 고려대학교, 2019년 가을학기.
지난 포스트와 이어지는 내용입니다. Batch Normalization, babysitting the learning process 그리고 hyperparameter optimization에 대해 다룹니다.
Batch Normalization
딥러닝의 고질적인 문제인 gradient explode/vanishing은 layer가 많아지면서 초기의 작은 변화가 많은 layer를 거치면서 누적되기 때문에 발생한다. 이는 학습 효율 저하 혹은 학습 실패를 야기하므로 반드시 해결해야 한다. 적절한 activation function과 weight initialization의 선택은 이 문제를 해결하기 위한 방법이었다. 한 가지 예로, sigmoid 활성화 함수를 사용하면 saturation이 발생하므로 ReLU라는 새로운 함수가 등장했다. 또한, 효율적인 학습을 위해 Xavier나 He 초기화를 사용하기도 했다. 하지만 layer가 일정 수 이상으로 많아지면 여전히 성공적으로 학습하지 못 하는 경우가 발생했다. Batch normalization은 앞선 방법들처럼 간접적인 방법이 아닌 학습 과정 자체를 안정화함으로써 본질적으로 문제를 해결하고자 제안되었다.
Internal Covariance Shift
We define Internal Covariate Shift as the change in the distribution of network activations due to the change in network parameters during training.
Batch normalization을 소개한 Ioffe & Szegedy는 학습 불안정의 원인이 internal covariance shift라고 설명한다. Internal covariance shift란 layer를 통과할 때마다 입력값의 분포가 변하는 것으로 이전 layer의 파라미터가 계속 update 되기 때문에 발생한다. 결국 학습이 반복될수록 뒤쪽 layer의 분포가 심하게 변하면서 학습이 잘 되지 않게 된다.
출처 : Debiprasad Ghosh
Internal covariance shift를 해결하기 위한 방법으로 whitening을 생각할 수 있다. Whitening은 입력값의 feature들이 uncorrelated이고 각각 분산 1을 가지게 만드는 과정이다. 하지만 이는 계산량이 많으며, 일부 파라미터가 무시될 수 있다는 문제가 있다. 입력값의 분산이 $\Sigma$라고 했을때 분산을 identity matrix로 만들기 위해 $\Sigma^{-1/2}$의 연산이 필요한데 이것은 많은 계산량을 요구한다. 또한, 입력값을 $u$, 출력값을 $x=u+b$ ($b$는 학습된 파라미터)로 하는 layer가 있다고 했을때, 평균을 빼는 과정 $x - E(x)$를 거치면 출력값에 $b$의 영향이 제거되고, 이는 결국 학습에 악영향을 준다. 표준화까지 하면 그 영향은 더 커진다고 한다. 때때로 미분불가능한 것도 whitening의 문제 중 하나이다.
Algorithm
Whitening의 문제를 보완하고, internal covariance shift를 해결하기 위해 논문에서는 다음의 알고리즘을 제시하였다.
많은 경우 mini-batch SGD 방법을 사용하므로, 비효율적인 입력값 전체의 full whitening보다는 batch의 feature별 정규화를 실시한다. 여기서 평균과 분산은 전체 training set에서 계산된다.
\[\hat{x}^{(k)} = \frac{x^{(k)} - E(x^{(k)})}{\sqrt{Var(x^{(k)})}}\]이러한 정규화는 feature들이 decorrelated되지 않더라도 수렴 속도를 가속화한다고 알려져 있다. 하지만, -1과 1 사이의 값을 가지게 만들기 때문에 특정 활성화 함수를 사용하면 비선형 함수를 선형 함수처럼 만들어 버릴 위험이 있다.
[-1,1] 범위로 제한되면 선형 함수와 비슷해진다.
이를 방지하기 위해 학습해야 하는 파라미터 $\gamma$ (scale factor)와 $\beta$ (shift factor)를 도입한다. 정규화된 $\hat{x}^{(k)}$에 이들을 추가한 $y^{(k)} = \gamma^{(k)} \hat{x}^{(k)} + \beta^{(k)}$를 출력값으로 활성화 함수에 건네준다. 경우에 따라 입력값을 그대로 출력값으로 내보내는 identity mapping도 가능하다. BN layer는 FC/convolutional layer 다음에, 활성화 함수 layer 전에 위치하여 별도로 평균과 분산을 바꾸는 것이 아닌 신경망 내에 존재한다는 것이 whitening과 구별되는 또다른 점이라고 할 수 있다.
BN 자체로 regularization 효과도 있어서 학습 속도를 느리게 하는 dropout를 제외할 수 있고, propagation에서 파라미터 scale의 영향을 받지 않으므로 learning rate를 크게 설정하여 속도를 빠르게 한다는 이점이 있다. Test나 convolutional layer를 사용할 경우, 다른 부분이 조금 있으니 논문을 통해 이를 확인하길 바란다.
Babysitting the Learning Process
처음부터 많은 양의 데이터를 전부 사용하기란 생각보다 쉽지 않다. 데이터의 양이 많아지면 학습 시간이 증가할텐데, 학습 중간에 오류를 발생하면 그것을 수정하는 데에 많은 시간과 노력이 필요하다. 이러한 번거로움을 피하기 위해 본격적인 학습에 앞서 적은 양의 데이터로 모의 학습을 해보자는 것이 이 절의 골자이다.
첫 번째 과정은 데이터 전처리이다. 적은 양의 데이터여도 전처리는 수행해야 한다. 이전 포스트에서 설명한 바가 있기 때문에 구체적으로 설명하지 않겠다. 한 가지만 덧붙이자면, 이미지 자료의 경우 값 자체가 의미를 지니고 있기 때문에 표준화를 하지 않는 경우가 많다. 두 번째 과정은 모델(혹은 신경망 구조)의 선택이다. 후보로 정한 여러 모델을 구체적으로 디자인하면 된다. Layer가 잘 구성되었는지 확인하기 위해 강의의 예시를 살펴보자.
규제화 없이 softmax를 사용한 경우
3장에서 softmax는 $-\log{x}$(밑은 자연상수 $e$이다)를 loss로 사용하는 것을 설명한 바가 있다. 예시의 경우, 10개의 클래스가 있으므로 규제를 하지 않았을 때 $\text{loss=} -\log{1/10} = 2.3$가 나와야 정상이다. 또한, 규제화 정도를 높이면 loss가 높아져야 한다. 이러한 점검 과정을 sanity check라고 하며 유사한 표현으로 double check, reality check 등이 있다.
loss가 조금 증가한 결과
이제 적은 양의 데이터로 학습을 진행하자. 데이터의 양이 적기 때문에 train accuracy가 100%인 overfitting 상태가 되어야 한다. 적절한 learning rate(학습 속도)를 찾는 것도 중요하다. 너무 작게 설정하면 학습이 너무 오래 걸리고, 너무 크게 설정하면 loss가 수렴하지 않을 수 있다. 가운데 그림과 같이 초반에는 빠르게 학습을 하고 점점 속도를 줄여가는 것이 효율적이다. 규제화 정도와 학습 속도 모두 분석가에 의해 결정되는 hyperparameter이기 때문에 지금처럼 적은 데이터를 사용해 대략적인 범위로 제한한 뒤, cross validation(교차 검증)을 통해 최종 선택하는 것이 올바르다.
출처 : Jeremy Jordan
Hyperparameter Optimization
A model hyperparameter is a configuration that is external to the model and whose value cannot be estimated from data.
이번 절에서는 hyperparameter(초모수)를 결정하는 방법에 대해 알아볼 것이다. 초모수는 데이터로부터 추정할 수 없는 값으로 학습을 통해 추정하는 parameter(모수)와 구분된다. Learning rate 혹은 k-NN의 k 등이 초모수에 해당하며, 어떤 값을 취하느냐에 따라 학습의 결과가 매우 달라지기 때문에 적절한 초모수의 선택은 굉장히 중요하다.
Cross Validation
초모수를 결정하기 위해서는 cross validation(교차 검증)을 먼저 알아야 한다. 교차 검증은 초모수의 결정뿐만 아니라 모형간 성능 비교와 overfitting(과대적합) 혹은 underfitting(과소적합)을 피하기 위해 사용한다. 과적합과 관련해서는 3장에서 설명한 바 있다. 구체적인 과정을 살펴보도록 하자.
교차 검증은 데이터를 분할하여 수행한다. (출처 : 고려대학교 통계적머신러닝 강의자료)
먼저 전체 데이터를 training set, validation set, test set로 분할한다. 각 데이터 셋의 역할은 다음과 같다.
- Training set을 이용하여 모델의 모수를 추정한다.
- Validation set을 이용하여 초모수를 결정한다. Test set에 사용할 성능이 좋은 모델을 선택하는 것이다. ex) 1-NN ~ 5-NN 중 어떤 모델이 성능이 좋은지 선택한다.
- Test data를 이용하여 최종 모델의 성능을 평가한다. 이것으로 모델간 성능을 비교할 수 있다. ex) Random Forest vs. SVM
모든 데이터 셋은 한 번 사용하면 다시 사용하지 않는다. 같은 데이터로 학습하고 평가하면 성능이 잘못 평가되므로 조금만 생각해보면 당연하다. 하지만, 위와 같이 한 번만 분할해서 학습하면 우연히 좋거나 나쁜 validation set을 택하는 경우가 발생할 수 있다. 우리는 새로운 데이터에 대해서도 성능이 좋은 모델을 원하기 때문에 validation set에 대해 unbiased한 초모수를 결정해야 한다. 따라서 다음의 K-fold cross validation 방법을 사용한다. 데이터가 작아서 validation set을 나누기 어려울 때에는 LOOCV(Leave-one-out cross validation) 방법을 사용하기도 한다.
반복을 통해 초모수를 결정한다. (출처 : 고려대학교 통계적머신러닝 강의자료)
$E_i$는 $i$번째 반복에서의 모델 성능이며, 예시의 경우 training set을 10개로 분할했으므로($K=10$) 총 10개의 값을 얻는다. 가장 우수한 $E = \dfrac{1}{10} \sum_{i=1}^{10} E_i$를 보이는 초모수를 선택한다. Test set으로 선택된 모델을 평가하면 최종 성능을 얻을 수 있다. Validation set과 test set 모두 모델의 성능을 평가하므로 차이가 없다고 생각할 수 있는데 그렇지 않다. Validation set은 여러 모델 중 하나를 선택하는 학습 과정에만 관여하는 데이터이고, test set은 최종 모델의 성능을 평가하는 과정에만 관여한다.
Nested Cross-Validation (출처 : 고려대학교 통계적머신러닝 강의자료)
K-fold CV는 초모수가 validation set에 의존하는 문제를 해결하긴 했지만, test set에 대해서는 해결하지 못했다. 고정된 test set(고정된 자료 분할 방식)으로 인해 발생하는 문제를 해결하기 위해 nested cross validation 방법이 사용된다. 모델의 최종 성능은 여러 개의 test performance를 평균 내어 얻는다.
Hyperparameter Tuning
어떤 기준으로 초모수를 선택해야 하는 지는 살펴보았으니, 이번에는 어떤 초모수를 후보로 해야 하는지 알아보자. 대표적으로 두 가지 방법이 있는데 각각 grid search와 random search이다. Grid search의 경우 각 초모수의 후보를 사전에 결정해놓고 모든 경우의 수를 고려하는 방법이다. 그러나 실제 최적값이 1.5인데 우리의 후보에는 1과 2만 있다면 최적의 초모수를 선택할 수 없다. 이러한 단점을 보완하기 위해 고안된 것이 random search이다. Random search는 각 초모수의 범위를 설정한 뒤 그 범위에서 랜덤으로 추출하여 선택하는 방법이다. 최근에는 더 개선된 다양한 방법이 제안되고 있으니 최신 동향을 살펴보길 권장한다.
Grid Search and Random Search
Loss curve와 train & test accuracy를 살펴보는 것도 좋은 방법이다. Loss curve를 시각화함으로써 learning rate가 너무 작거나 큰 지 확인할 수도 있으며, 초기화가 적절하게 되었는지 판단할 수 있다.
Loss curve를 시각화한 모습
왼쪽 그림과 같이 loss가 좀처럼 줄어들지 않다가 갑자기 학습이 잘 진행된다면 다른 초기화 방법을 적용해서 학습 효율을 개선시킬 수 있다. 또한, train & test accuracy가 오른쪽 그림과 같은 양상을 보인다면 규제화 정도를 증가시키면 될 것이다. 이처럼 수치뿐만 아니라 시각화를 통해 효율적이고 직관적인 초모수 결정이 가능하다.
시각화를 통해 학습을 점검할 수 있다.
지금까지 모델 학습에 대한 전반적인 과정을 살펴보았다. 각 과정들이 분리된 것이 아니라 유기적으로 연결되어 있기 때문에 한 번 공부한다고 익힐 수 있는 내용들이 아니다. 또한 절대적인 규칙이 존재하지 않기 때문에 다양한 데이터를 분석해보고 시행착오를 겪으면서 경험을 습득하는 것이 무엇보다도 중요하다. 각자의 데이터와 분석 목적이 다를텐데 ‘이렇게 하면 성능이 좋다’는 말만 듣고 따라하기만 한다면 실력은 제자리 걸음만 할 뿐이다.
Further Reading
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Batch Normalization 설명 및 구현
- [Part IV. CNN 핵심 요소 기술 ] 1. Batch Normalization [1] -라온피플 머신러닝 아카데미-
- [Deep Learning] Batch Normalization 개념 정리
- Why does batch normalization help?
- Setting the learning rate of your neural network.
- What is the Difference Between a Parameter and a Hyperparameter?
- 3.1. Cross-validation: evaluating estimator performance
- 박유성. “통계적머신러닝” 고려대학교, 2019년 가을학기.