
[CS231n]Lecture 3-Loss Functions and Optimization
25 Jan 2020 | CS231n
Lecture 3-Loss Functions and Optimization와 강의자료를 참고하여 개인적으로 정리한 글입니다.
$n$ x $n$ x 3차원의 Image input $x$와 $W$(parameters 혹은 weights)에 대하여 $f(x,W)=Wx+b$를 연산하면 각 labels에 대한 scores를 구할 수 있다. 정답인 label의 score가 가장 높다면, 우리의 분류기는 입력 이미지를 잘 분류한 것이다. 당연하게도 이미지 분류의 최종적인 목표는 임의의 이미지를 최대한 잘 분류하는 것인데, 이는 $W$를 찾는 것으로 귀결된다. 그렇다면 $W$를 어떻게 찾아야 할까?
Loss Functions
TODO 1 : Define a loss function that quantifies our unhappiness with the scores across the training data.
Training data를 학습할 때 그 단계에서 얼마나 틀리게 분류했는지 수치화할 필요가 있는데 그것이 loss function(손실 함수)의 역할이다. 결국 우리의 목표는 loss function을 최소화하는 $W$를 찾는 것이다. 어떻게 최소화하는가에 대한 문제는 뒤의 optimization(최적화)에서 다루겠다. Loss function의 정의는 다음과 같다.
\[L = \frac{1}{N} \sum_i{L_i(f(x_i,W),y_i)} \text{ where } x_i \text{ is image and } y_i \text{ is label.}\]
우리의 분류기가 계산한 $f(x_i,W)$와 정답인 $y_i$와의 차이를 계산 하고 이를 모두 더해 평균을 낸 것이다. 여기서는
- Multiclass SVM loss
- Cross Entropy
- MSE(Mean of Squared Error)
를 소개하려고 한다. 1번은 강의에서 소개된 것이고, 나머지 둘은 자주 사용되는 것이다.
Multiclass SVM loss
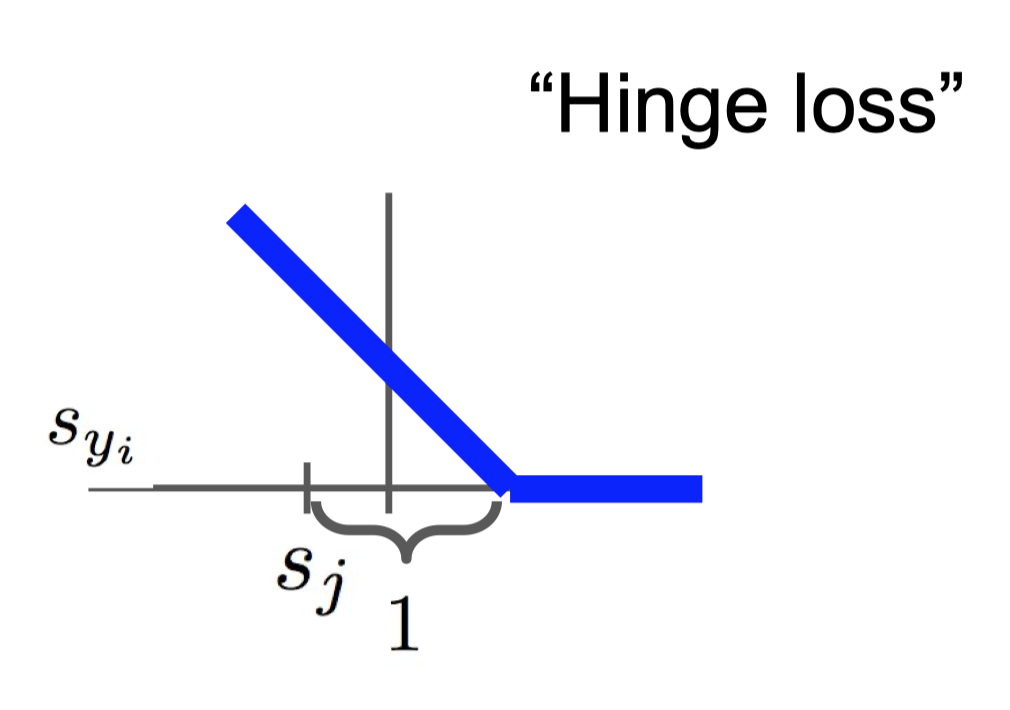
Multiclass SVM loss의 정의는 다음과 같다.
\[loss = \frac{1}{N} \sum_i \sum_{j \neq y_i} max(0, s_j-s_{y_i}+1)\]
$s_i = f(x_i,W)$는 $i$번째 클래스의 출력값을 의미한다. SVM loss는 경첩모양이어서 hinge loss라고도 한다. 예시를 통해 어떻게 계산하는지 살펴보자.

CIFAR-10 training data의 일부인데, 10개의 클래스는 너무 많으니 3개만 살펴보자. 첫번째 사진의 정답 label은 고양이이다. 따라서 고양이 클래스를 제외한 나머지 클래스의 $s_j$와 $s_{cat}$로 계산한다. 즉, 첫번째 이미지의 loss는 $max(0, 5.1-3.2+1) + max(0, -1.7-3.2+1)=2.9$이다. 이런식으로 나머지 이미지들의 loss를 계산해보면, 각각 0과 12.9가 되겠다.
Multiclass SVM loss의 특징
- 식을 유심히 살펴보면 알 수 있겠지만, 이 loss function은 정답인 label의 $s$값이 가장 크면 0의 값을, 그렇지 않으면 양수의 값을 반환해준다. 세번째 이미지처럼 정답인 label의 $s$값이 너무 작으면 loss가 점점 커지는 것을 확인할 수 있다. 또한, 정답 label의 값이 가장 크기만 하면, 다른 값들이 어떻든 상관없이 0의 값을 반환한다.(위의 hinge loss 그림 참고)
- $s_j-s_{y_i}+1$에서 1은 safety margin이다. 정답 클래스와 오답 클래스의 차이가 1 이상이면 loss를 0으로 주겠다는 의미이다. output score에 따라 설정해주면 된다. 예를 들어, 0과 1사이의 output score 때에는 1은 매우 큰 값이니까 더 작은 값을 줘야할 것이고, 매우 큰 output score라면 1은 의미가 없는 수준일 것이다.
- 최솟값은 0, 최댓값 $\infty$이다.
- 모든 $s$값이 0에 가까운 값을 가지면 (클래스의 수)-1의 값을 가진다. 이는 초기 학습 단계에서 debug procedure에서 유용하게 이용할 수 있다. 초기에는 $W$가 작으므로 (클래수의 수)-1의 값을 가질 확률이 높기 때문이다.
- 정답 label을 계산에 포함시켜도 단순히 1씩 증가할 뿐 의미가 없다.
- 합계 대신 평균을 사용하더라도 $N$은 고정이기 때문에 scaling 하는 것일 뿐이어서 의미가 없다.
- 제곱의 값($max^2$)을 사용하면 틀렸을 경우 loss를 더 크게 준다. Squared hinge loss라고도 한다.
Cross Entropy
분류에서 주로 사용하는 Cross Entropy의 정의는 다음과 같다.
\[loss = -\frac{1}{N} \sum_i t_i \log(S(s_i))\]
$t_i$는 각 클래스에 대한 라벨값이며 one-hot encoding 값이다. $s_i$는 위와 동일하고, $S(\cdot)$은 softmax activation function이다. 항상 softmax 값이 대입되지는 않지만 대부분 함께 사용한다. 먼저 softmax 함수를 알아보도록 하자.
Softmax
Softmax activation function의 정의는 다음과 같다.
\[S(s_i) = \frac{e^{s_i}}{\sum_j{e^{s_j}}}\]
간단히 말하자면, 각 class의 최종 output을 normalized하여 각 클래스에 속할 확률(0과 1사이의 값)을 계산하는 것이다. 예를 들어, 위의 첫 번째 이미지에 대한 softmax 값은 이렇게 계산한다.
\[\frac{e^{3.2}}{e^{3.2}+e^{5.1}+e^{-1.7}}=0.129\]
\[\frac{e^{5.1}}{e^{3.2}+e^{5.1}+e^{-1.7}}=0.869\]
\[\frac{e^{-1.7}}{e^{3.2}+e^{5.1}+e^{-1.7}}=0.001\]
다시 cross entropy로 돌아와서 이제 전체 loss를 구해보자. 먼저 첫 번째 이미지에 대한 loss는
\[1*\log(0.129) + 0*\log(0.869) + 0*\log(0.001) = \log(0.129)\]
정답 클래스는 첫번째이므로 0.129만이 선택된다. 같은 방식으로 두번째, 세번째 이미지의 loss는 각각 $\log(0.924), \log(0.002)$이다. 따라서 최종 loss는
\[-\frac{\log(0.129)+\log(0.924)+\log(0.002)}{3}=2.78\]
Hinge loss는 loss를 계산할 때 $s_i$를 바로 사용했지만, cross entropy는 0과 1사이의 값으로 바꾼 다음 계산하는 것이 차이점이다. 또한, hinge loss는 정답 클래스의 값이 가장 높으면 0으로 loss를 부여하고 그 값이 어떻든 신경 쓰지 않았다. 하지만, cross entropy는 얼마나 정확하게 분류했는지까지 수치화한다.
한 가지 더 짚고 넘어가자면, $y=\log{x}$의 그래프는 다음과 같은데 $x$값이 1과 가까울수록 0에 가까워지고, 0과 가까울수록 $-\infty$에 가까워진다. 따라서 정답 클래스의 softmax 값이 클수록(1에 가까울수록) loss는 0에 가까워진다. 전체 식에서 $-$부호가 있는 것은 정답 클래스의 값이 낮아질수록 loss가 커지게 하기 위함이다.
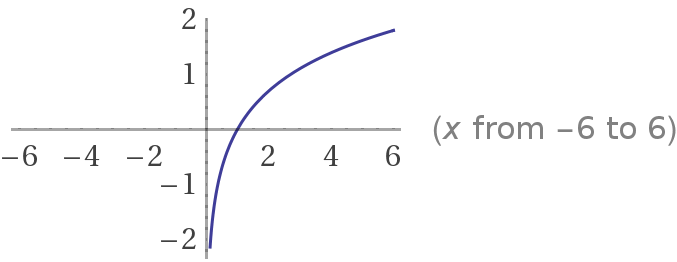
MSE
회귀에서 많이 쓰이는 MSE(Mean of Squared Error, 평균 제곱 오차)의 정의는 다음과 같다.
\[\frac{1}{N} \sum_i (S(s_i)-t_i)^2\]
식의 기호는 cross entropy와 동일하다. 위의 예시의 MSE를 구해보자. 각 이미지의 MSE는 다음과 같다.
\[(0.129-1)^2 + (0.869-0)^2 + (0.001-0)^2 = 1.51\]
Regularization
지금까지 어떤 손실함수가 있는지 살펴보았고, 각각의 특징을 알아보았다. 손실함수는 우리가 최소화해야할 목표임을 기억하자. 하지만, 손실함수를 과하게 최소화하면 문제가 생긴다.
Training data로부터 손실 함수를 최소화하는 parameter $W$를 찾는 것은 좋은데, 우리의 최종 목표는 새로운 데이터(test data)도 잘 맞추는 일반화된(generalized) 분류기를 찾는 것이다. 따라서 training data에 너무 최적화된(손실함수를 과도하게 최소화한) $W$는 새로운 데이터에 잘 맞지 않을 가능성이 높다. 이러한 상황을 overfitting(과적합)이라고 하며 overfitting을 피하기 위한 방법으로 regularization(정규화)가 있다.
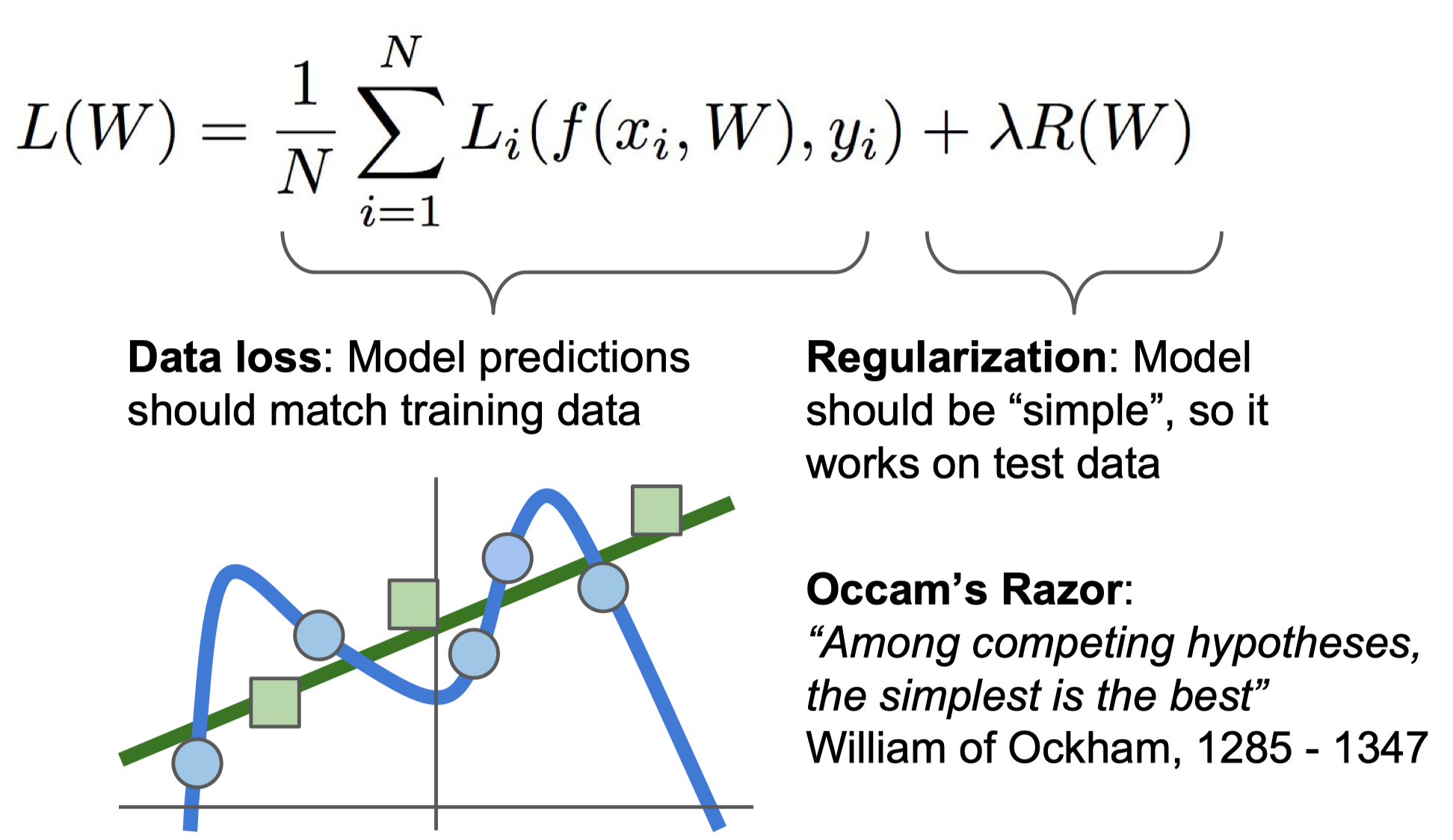
그림에서 파란 원은 training data이고, 초록색 사각형은 test data이다. 파란 선은 training data에 아주 잘 맞지만(overfitting), test data에는 하나도 맞지 않는다. 따라서 우리는 초록색 선처럼 새로운 데이터에 대해서도 어느정도 맞는 결과를 원한다.
손실 함수 $L(W)$에 $R(W)$(regularization term)를 더함으로써 과적합을 피할 수 있다. 직관적으로 설명하자면, $L(W)$를 최소화하되 $R(W)$가 커지는 것을 극복하면서 최소화하라는 의미이다. 정규화의 종류로는
- L1 regularization
- L2 regularization
- Elastic net
- Dropout
등이 있다. Elastic net은 L1과 L2의 혼합이고, Dropout은 딥러닝에서 주로 사용하는 방법이다.
L1 Regularization
L1 regularization term의 식은 다음과 같다.
\[R(W)=\sum_k \sum_l |W_{k,l}|\]
L1 정규화 항을 추가하면 변수 선택의 효과를 얻을 수 있다. 이는 특정한 $W_{k,l}$가 0이 되기 때문이다. 따라서 $W$가 sparse해지면서 초록색 선과 같은 단순한 결과를 얻게 된다.
그렇다면 왜 L1 정규화 항이 특정 $W_{k,l}$를 0으로 만드는 것일까? 전체 손실 함수를 다시 한번 살펴보자.
\[L(W) = \frac{1}{N} \sum_i{L_i(f(x_i,W),y_i)} + \lambda \sum_k \sum_l |W_{k,l}|\]
손실 함수를 최소화하면 할수록 왼쪽 항의 값은 작아지지만, 모델이 복잡해지면서(파란 선의 모습) 오른쪽 항의 값이 커지게 된다. 따라서 특정 $W_{k,l}$의 값을 줄이는 과정이 발생한다. 또한 L1 정규화 항은 laplace prior( $laplace(0, \frac{1}{\lambda})$ )를 사용하는 MAP inference와 동치이다.
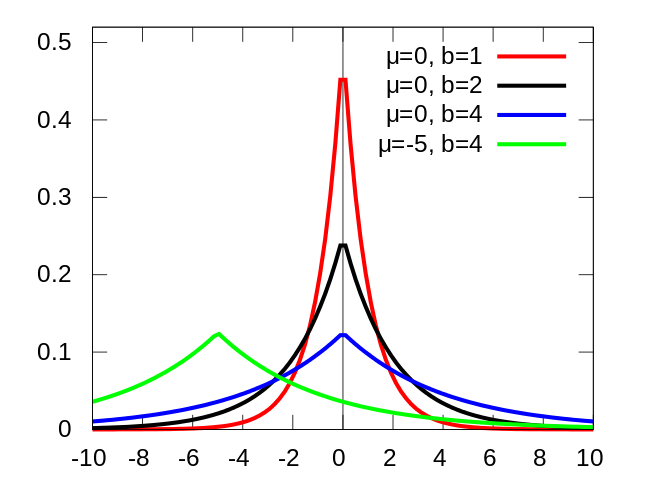
중심이 0인 laplace 분포는 0의 값을 가질 확률이 높기 때문에 특정 $W_{k,l}$의 값이 0이 된다. 정규화 항 앞에 있는 $\lambda$는 정규화 세기를 설정하는 hyperparameter인데, $\lambda$가 커질수록 laplace 분포는 점점 더 중앙에 집중되는 모습을 가진다. 따라서 정규화를 강하게 할수록 0의 값을 갖는 $W_{k,l}$이 많아진다.
L2 Regularization
L2 정규화 항의 식은 다음과 같다.
\[R(W)=\sum_k \sum_l W_{k,l}^2\]
L2 정규화 항은 Gaussian prior( $N(0, \frac{1}{2\lambda})$ ) 를 사용하는 MAP inference와 동치이다.
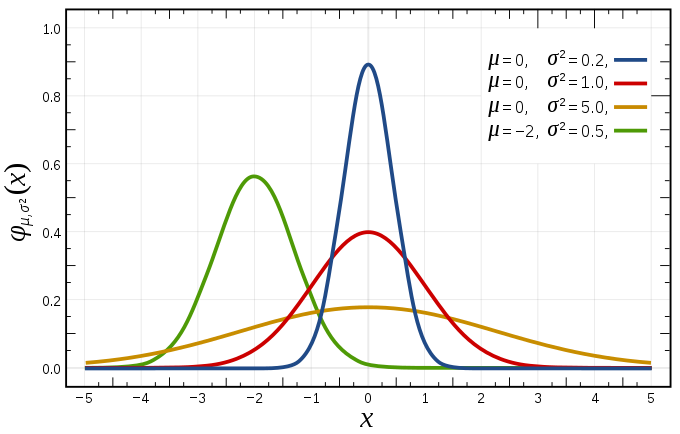
중심이 0인 정규분포는 laplace 분포에 비해 0의 확률이 낮기 때문에 특정 $W_{k,l}$이 정확히 0의 값을 갖기보다 0에 수렴하는 값을 가진다.
Optimization
TODO 2 : Come up with a way of efficiently finding the parameters that minimize the loss function.
$W$를 찾을 때에는 loss function을 최소화하는 $W$를 찾아야 하는데 어떻게 찾아야할까? 무작위로 값을 대입하면서 원하는 $W$를 기대하기에는 확실하지도 않고 굉장히 비효율적이다. 따라서 우리는 효율적으로 정답을 찾을 필요가 있고 그 과정이 optimization(최적화)이다.
Gradient Descent
앞이 보이지 않는 깜깜한 산에서 내려가는 방법을 생각해보자. 아마도 발을 이리저리 디디면서 아래쪽이라고 생각되는 방향으로 한 발짝씩 나아갈 것이다. Gradient Descent(GD, 경사 하강법)는 이러한 아이디어에 기반한 최솟값을 찾는 방법이다. 식은 다음과 같다.
\[W_{i+1} = W_i - \eta \nabla L_W\]
구체적인 과정을 살펴보면,
- Hyperparameter $\eta$ (learning rate, 학습률)를 설정한다. 보폭의 크기를 정한다고 생각하면 된다.
- 초깃값 $W_0$와 training data를 이용해 loss를 구하고 gradient($\nabla L_W$)를 계산해서 loss가 최소가 되는 방향을 찾는다.
- $W_1 = W_0 - \eta \nabla L_W$의 식을 이용해 $W_1$로 업데이트한다.
- Loss function를 최소화하는 $W$로 수렴할때까지 1~3번 과정을 반복한다.
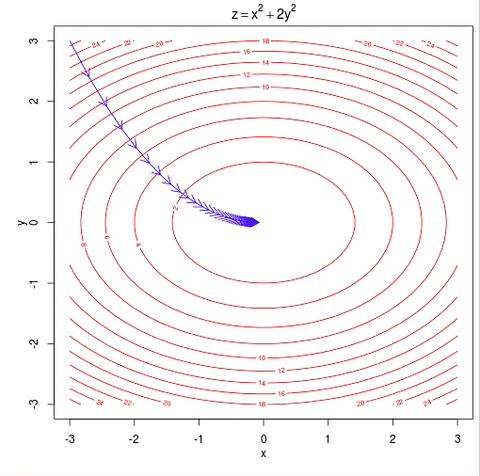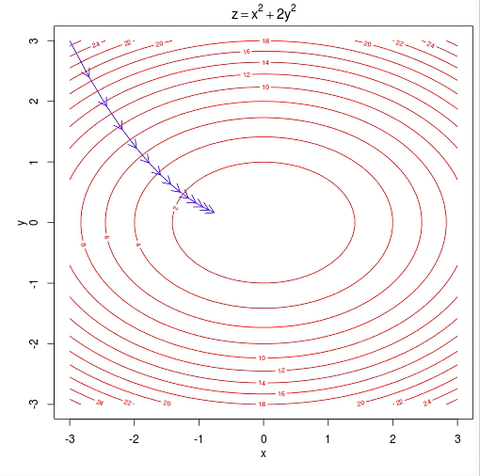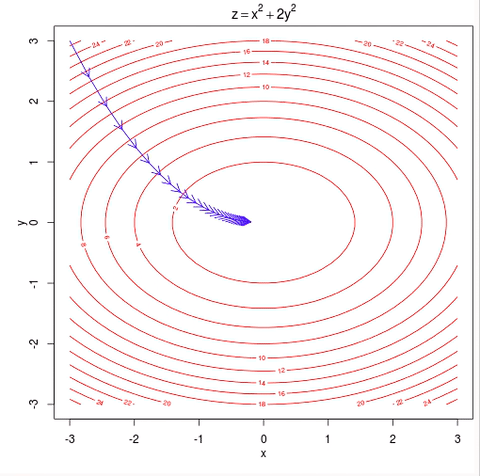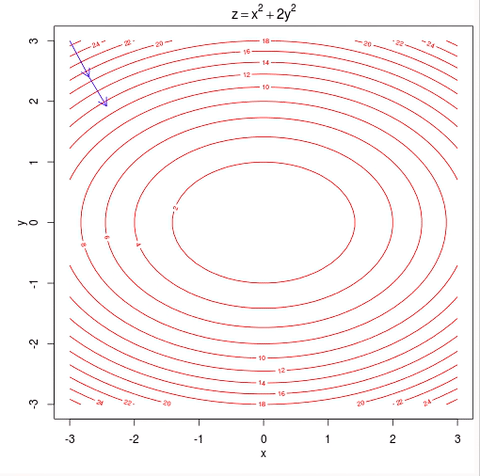
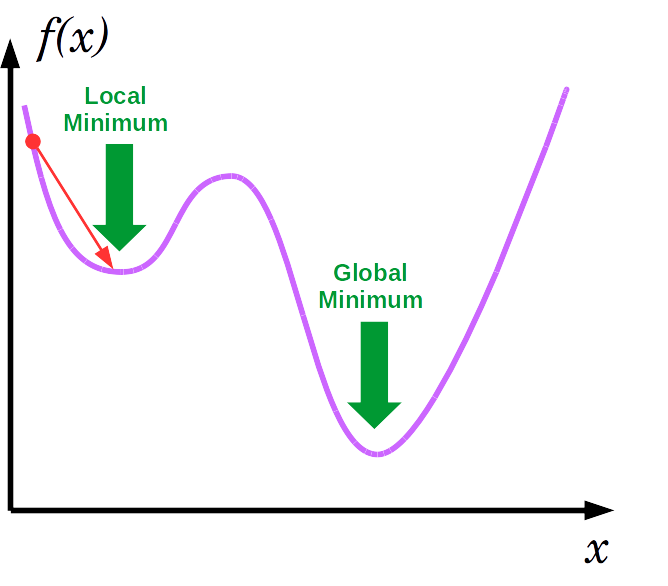
언뜻보면 굉장히 간단하고 문제가 없어보이지만 몇가지 문제가 있다. 첫 번째로 local minima에 빠질 위험이 있다. 위의 그림처럼 최종적으로 도달하는 곳이 loss function이 최솟값을 갖는 곳이면 문제가 없지만 아래와 같이 빨간 점에서 시작한다면 local minima에 빠져버리게 된다.
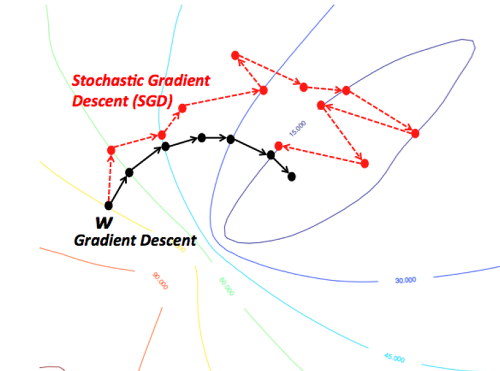
두 번째는 속도가 굉장히 느려질 수 있다는 점이다. 10만개의 training data가 있다고 하자. 그러면 2번 과정에서 loss와 gradient를 구할때 10만개의 데이터를 전부 사용해야 한다. 데이터가 100만, 1000만, 그 이상으로 커진다면? 한 번 학습할 때 너무 많은 시간이 소요된다.
Batch size, Epoch, Iteration
GD의 문제점을 해결하기 전에 몇가지 용어를 정리하자.
Epoch
One Epoch is when an ENTIRE dataset is passed forward and backward through the neural network only ONCE
딥러닝에서 학습과정은 데이터의 입력부터 출력까지의 forward pass(순방향 과정)와 출력으로부터 $W$를 업데이트하는 backward pass(역방향 과정)로 구분할 수 있다. 전체 데이터 셋에 대해 순방향+역방향 과정이 한 번씩 완료되면 1 epoch이 완료되었다고 한다.
Batch size
Total number of training examples present in a single batch.
Batch(배치)의 사전적 의미는 일괄적으로 처리되는 집단이다. 배치는 한 번에 여러개의 데이터를 묶어서 입력하는 것인데, GPU의 병렬 연산 기능을 최대한 효율적으로 사용하기 위해 쓰는 방법이다. 딥러닝 계산 방식은 행렬 연산이므로 1개씩 100번이 아닌 100개씩 1번에 계산할 수 있다. Batch size는 한 번의 배치마다 사용할 데이터의 양을 의미한다.
Iteration
The number of passes to complete one epoch.
Iteration은 1 epoch을 완료하기 위해 학습해야 하는 횟수를 의미한다.
전체 데이터 셋이 1000개일 때 batch size를 10으로 설정하면 1 iteration에 10개의 데이터를 사용하고 100 iteration하면 1 epoch이 완료된다.
Stochastic Gradient Descent
GD의 문제를 해결하기 위한 첫번째 방법으로 Stochastic Gradient Descent(SGD, 확률적 경사하강법)가 있다. SGD는 입력 데이터를 단 한 개만 사용하는 방법이다. 따라서 1 iteration에 걸리는 시간이 짧기 때문에 수렴 속도가 상대적으로 빠르다. 또한 한 개의 데이터를 사용했으므로 아래의 그림처럼 shooting이 발생하여 local minima에 빠질 위험이 적다.
Shooting이 발생해서 더 많은 학습이 필요하지만 1 iteration이 월등히 빠르기 때문에 수렴 속도가 빠르다.
하지만 단점으로는 shooting 때문에 global minimum도 찾지 못 할 가능성이 있으며 GPU의 성능을 전부 활용할 수 없다.
Mini-batch Gradient Descent
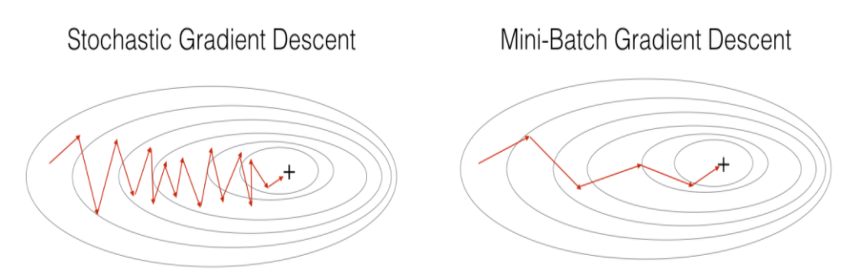
GD와 SGD의 장점만을 모은 것이 Mini-batch Gradient Descent(미니배치 경사하강법)이다. SGD가 입력 데이터를 단 한 개 사용했다면 MGD는 여러개 사용한다. 따라서 SGD보다 병렬처리에 유리하며 여전히 shooting이 발생하므로 local minima에 빠질 위험이 적다. 하지만, batch size를 잘 설정해야 하며 SGD보다 메모리 사용량이 높다.
Other Optimizers
GD, SGD, MGD 외에도 여러 optimizer가 있다. 크게 adaptive 계열과 momentum 계열이 있는데 최근에는 두 가지가 혼합된 Adam이 주로 사용된다. 이들은 7강에서 이야기하겠다.
Lecture 3-Loss Functions and Optimization와 강의자료를 참고하여 개인적으로 정리한 글입니다.
$n$ x $n$ x 3차원의 Image input $x$와 $W$(parameters 혹은 weights)에 대하여 $f(x,W)=Wx+b$를 연산하면 각 labels에 대한 scores를 구할 수 있다. 정답인 label의 score가 가장 높다면, 우리의 분류기는 입력 이미지를 잘 분류한 것이다. 당연하게도 이미지 분류의 최종적인 목표는 임의의 이미지를 최대한 잘 분류하는 것인데, 이는 $W$를 찾는 것으로 귀결된다. 그렇다면 $W$를 어떻게 찾아야 할까?
Loss Functions
TODO 1 : Define a loss function that quantifies our unhappiness with the scores across the training data.
Training data를 학습할 때 그 단계에서 얼마나 틀리게 분류했는지 수치화할 필요가 있는데 그것이 loss function(손실 함수)의 역할이다. 결국 우리의 목표는 loss function을 최소화하는 $W$를 찾는 것이다. 어떻게 최소화하는가에 대한 문제는 뒤의 optimization(최적화)에서 다루겠다. Loss function의 정의는 다음과 같다.
\[L = \frac{1}{N} \sum_i{L_i(f(x_i,W),y_i)} \text{ where } x_i \text{ is image and } y_i \text{ is label.}\]우리의 분류기가 계산한 $f(x_i,W)$와 정답인 $y_i$와의 차이를 계산 하고 이를 모두 더해 평균을 낸 것이다. 여기서는
- Multiclass SVM loss
- Cross Entropy
- MSE(Mean of Squared Error)
를 소개하려고 한다. 1번은 강의에서 소개된 것이고, 나머지 둘은 자주 사용되는 것이다.
Multiclass SVM loss
Multiclass SVM loss의 정의는 다음과 같다.
\[loss = \frac{1}{N} \sum_i \sum_{j \neq y_i} max(0, s_j-s_{y_i}+1)\]$s_i = f(x_i,W)$는 $i$번째 클래스의 출력값을 의미한다. SVM loss는 경첩모양이어서 hinge loss라고도 한다. 예시를 통해 어떻게 계산하는지 살펴보자.
CIFAR-10 training data의 일부인데, 10개의 클래스는 너무 많으니 3개만 살펴보자. 첫번째 사진의 정답 label은 고양이이다. 따라서 고양이 클래스를 제외한 나머지 클래스의 $s_j$와 $s_{cat}$로 계산한다. 즉, 첫번째 이미지의 loss는 $max(0, 5.1-3.2+1) + max(0, -1.7-3.2+1)=2.9$이다. 이런식으로 나머지 이미지들의 loss를 계산해보면, 각각 0과 12.9가 되겠다.
Multiclass SVM loss의 특징
- 식을 유심히 살펴보면 알 수 있겠지만, 이 loss function은 정답인 label의 $s$값이 가장 크면 0의 값을, 그렇지 않으면 양수의 값을 반환해준다. 세번째 이미지처럼 정답인 label의 $s$값이 너무 작으면 loss가 점점 커지는 것을 확인할 수 있다. 또한, 정답 label의 값이 가장 크기만 하면, 다른 값들이 어떻든 상관없이 0의 값을 반환한다.(위의 hinge loss 그림 참고)
- $s_j-s_{y_i}+1$에서 1은 safety margin이다. 정답 클래스와 오답 클래스의 차이가 1 이상이면 loss를 0으로 주겠다는 의미이다. output score에 따라 설정해주면 된다. 예를 들어, 0과 1사이의 output score 때에는 1은 매우 큰 값이니까 더 작은 값을 줘야할 것이고, 매우 큰 output score라면 1은 의미가 없는 수준일 것이다.
- 최솟값은 0, 최댓값 $\infty$이다.
- 모든 $s$값이 0에 가까운 값을 가지면 (클래스의 수)-1의 값을 가진다. 이는 초기 학습 단계에서 debug procedure에서 유용하게 이용할 수 있다. 초기에는 $W$가 작으므로 (클래수의 수)-1의 값을 가질 확률이 높기 때문이다.
- 정답 label을 계산에 포함시켜도 단순히 1씩 증가할 뿐 의미가 없다.
- 합계 대신 평균을 사용하더라도 $N$은 고정이기 때문에 scaling 하는 것일 뿐이어서 의미가 없다.
- 제곱의 값($max^2$)을 사용하면 틀렸을 경우 loss를 더 크게 준다. Squared hinge loss라고도 한다.
Cross Entropy
분류에서 주로 사용하는 Cross Entropy의 정의는 다음과 같다.
\[loss = -\frac{1}{N} \sum_i t_i \log(S(s_i))\]$t_i$는 각 클래스에 대한 라벨값이며 one-hot encoding 값이다. $s_i$는 위와 동일하고, $S(\cdot)$은 softmax activation function이다. 항상 softmax 값이 대입되지는 않지만 대부분 함께 사용한다. 먼저 softmax 함수를 알아보도록 하자.
Softmax
Softmax activation function의 정의는 다음과 같다.
\[S(s_i) = \frac{e^{s_i}}{\sum_j{e^{s_j}}}\]간단히 말하자면, 각 class의 최종 output을 normalized하여 각 클래스에 속할 확률(0과 1사이의 값)을 계산하는 것이다. 예를 들어, 위의 첫 번째 이미지에 대한 softmax 값은 이렇게 계산한다.
\[\frac{e^{3.2}}{e^{3.2}+e^{5.1}+e^{-1.7}}=0.129\] \[\frac{e^{5.1}}{e^{3.2}+e^{5.1}+e^{-1.7}}=0.869\] \[\frac{e^{-1.7}}{e^{3.2}+e^{5.1}+e^{-1.7}}=0.001\]다시 cross entropy로 돌아와서 이제 전체 loss를 구해보자. 먼저 첫 번째 이미지에 대한 loss는
\[1*\log(0.129) + 0*\log(0.869) + 0*\log(0.001) = \log(0.129)\]정답 클래스는 첫번째이므로 0.129만이 선택된다. 같은 방식으로 두번째, 세번째 이미지의 loss는 각각 $\log(0.924), \log(0.002)$이다. 따라서 최종 loss는
\[-\frac{\log(0.129)+\log(0.924)+\log(0.002)}{3}=2.78\]Hinge loss는 loss를 계산할 때 $s_i$를 바로 사용했지만, cross entropy는 0과 1사이의 값으로 바꾼 다음 계산하는 것이 차이점이다. 또한, hinge loss는 정답 클래스의 값이 가장 높으면 0으로 loss를 부여하고 그 값이 어떻든 신경 쓰지 않았다. 하지만, cross entropy는 얼마나 정확하게 분류했는지까지 수치화한다.
한 가지 더 짚고 넘어가자면, $y=\log{x}$의 그래프는 다음과 같은데 $x$값이 1과 가까울수록 0에 가까워지고, 0과 가까울수록 $-\infty$에 가까워진다. 따라서 정답 클래스의 softmax 값이 클수록(1에 가까울수록) loss는 0에 가까워진다. 전체 식에서 $-$부호가 있는 것은 정답 클래스의 값이 낮아질수록 loss가 커지게 하기 위함이다.
MSE
회귀에서 많이 쓰이는 MSE(Mean of Squared Error, 평균 제곱 오차)의 정의는 다음과 같다.
\[\frac{1}{N} \sum_i (S(s_i)-t_i)^2\]식의 기호는 cross entropy와 동일하다. 위의 예시의 MSE를 구해보자. 각 이미지의 MSE는 다음과 같다.
\[(0.129-1)^2 + (0.869-0)^2 + (0.001-0)^2 = 1.51\]Regularization
지금까지 어떤 손실함수가 있는지 살펴보았고, 각각의 특징을 알아보았다. 손실함수는 우리가 최소화해야할 목표임을 기억하자. 하지만, 손실함수를 과하게 최소화하면 문제가 생긴다.
Training data로부터 손실 함수를 최소화하는 parameter $W$를 찾는 것은 좋은데, 우리의 최종 목표는 새로운 데이터(test data)도 잘 맞추는 일반화된(generalized) 분류기를 찾는 것이다. 따라서 training data에 너무 최적화된(손실함수를 과도하게 최소화한) $W$는 새로운 데이터에 잘 맞지 않을 가능성이 높다. 이러한 상황을 overfitting(과적합)이라고 하며 overfitting을 피하기 위한 방법으로 regularization(정규화)가 있다.
그림에서 파란 원은 training data이고, 초록색 사각형은 test data이다. 파란 선은 training data에 아주 잘 맞지만(overfitting), test data에는 하나도 맞지 않는다. 따라서 우리는 초록색 선처럼 새로운 데이터에 대해서도 어느정도 맞는 결과를 원한다.
손실 함수 $L(W)$에 $R(W)$(regularization term)를 더함으로써 과적합을 피할 수 있다. 직관적으로 설명하자면, $L(W)$를 최소화하되 $R(W)$가 커지는 것을 극복하면서 최소화하라는 의미이다. 정규화의 종류로는
- L1 regularization
- L2 regularization
- Elastic net
- Dropout
등이 있다. Elastic net은 L1과 L2의 혼합이고, Dropout은 딥러닝에서 주로 사용하는 방법이다.
L1 Regularization
L1 regularization term의 식은 다음과 같다.
\[R(W)=\sum_k \sum_l |W_{k,l}|\]L1 정규화 항을 추가하면 변수 선택의 효과를 얻을 수 있다. 이는 특정한 $W_{k,l}$가 0이 되기 때문이다. 따라서 $W$가 sparse해지면서 초록색 선과 같은 단순한 결과를 얻게 된다.
그렇다면 왜 L1 정규화 항이 특정 $W_{k,l}$를 0으로 만드는 것일까? 전체 손실 함수를 다시 한번 살펴보자.
\[L(W) = \frac{1}{N} \sum_i{L_i(f(x_i,W),y_i)} + \lambda \sum_k \sum_l |W_{k,l}|\]손실 함수를 최소화하면 할수록 왼쪽 항의 값은 작아지지만, 모델이 복잡해지면서(파란 선의 모습) 오른쪽 항의 값이 커지게 된다. 따라서 특정 $W_{k,l}$의 값을 줄이는 과정이 발생한다. 또한 L1 정규화 항은 laplace prior( $laplace(0, \frac{1}{\lambda})$ )를 사용하는 MAP inference와 동치이다.
중심이 0인 laplace 분포는 0의 값을 가질 확률이 높기 때문에 특정 $W_{k,l}$의 값이 0이 된다. 정규화 항 앞에 있는 $\lambda$는 정규화 세기를 설정하는 hyperparameter인데, $\lambda$가 커질수록 laplace 분포는 점점 더 중앙에 집중되는 모습을 가진다. 따라서 정규화를 강하게 할수록 0의 값을 갖는 $W_{k,l}$이 많아진다.
L2 Regularization
L2 정규화 항의 식은 다음과 같다.
\[R(W)=\sum_k \sum_l W_{k,l}^2\]L2 정규화 항은 Gaussian prior( $N(0, \frac{1}{2\lambda})$ ) 를 사용하는 MAP inference와 동치이다.
중심이 0인 정규분포는 laplace 분포에 비해 0의 확률이 낮기 때문에 특정 $W_{k,l}$이 정확히 0의 값을 갖기보다 0에 수렴하는 값을 가진다.
Optimization
TODO 2 : Come up with a way of efficiently finding the parameters that minimize the loss function.
$W$를 찾을 때에는 loss function을 최소화하는 $W$를 찾아야 하는데 어떻게 찾아야할까? 무작위로 값을 대입하면서 원하는 $W$를 기대하기에는 확실하지도 않고 굉장히 비효율적이다. 따라서 우리는 효율적으로 정답을 찾을 필요가 있고 그 과정이 optimization(최적화)이다.
Gradient Descent
앞이 보이지 않는 깜깜한 산에서 내려가는 방법을 생각해보자. 아마도 발을 이리저리 디디면서 아래쪽이라고 생각되는 방향으로 한 발짝씩 나아갈 것이다. Gradient Descent(GD, 경사 하강법)는 이러한 아이디어에 기반한 최솟값을 찾는 방법이다. 식은 다음과 같다.
\[W_{i+1} = W_i - \eta \nabla L_W\]구체적인 과정을 살펴보면,
- Hyperparameter $\eta$ (learning rate, 학습률)를 설정한다. 보폭의 크기를 정한다고 생각하면 된다.
- 초깃값 $W_0$와 training data를 이용해 loss를 구하고 gradient($\nabla L_W$)를 계산해서 loss가 최소가 되는 방향을 찾는다.
- $W_1 = W_0 - \eta \nabla L_W$의 식을 이용해 $W_1$로 업데이트한다.
- Loss function를 최소화하는 $W$로 수렴할때까지 1~3번 과정을 반복한다.
언뜻보면 굉장히 간단하고 문제가 없어보이지만 몇가지 문제가 있다. 첫 번째로 local minima에 빠질 위험이 있다. 위의 그림처럼 최종적으로 도달하는 곳이 loss function이 최솟값을 갖는 곳이면 문제가 없지만 아래와 같이 빨간 점에서 시작한다면 local minima에 빠져버리게 된다.
두 번째는 속도가 굉장히 느려질 수 있다는 점이다. 10만개의 training data가 있다고 하자. 그러면 2번 과정에서 loss와 gradient를 구할때 10만개의 데이터를 전부 사용해야 한다. 데이터가 100만, 1000만, 그 이상으로 커진다면? 한 번 학습할 때 너무 많은 시간이 소요된다.
Batch size, Epoch, Iteration
GD의 문제점을 해결하기 전에 몇가지 용어를 정리하자.
Epoch
One Epoch is when an ENTIRE dataset is passed forward and backward through the neural network only ONCE
딥러닝에서 학습과정은 데이터의 입력부터 출력까지의 forward pass(순방향 과정)와 출력으로부터 $W$를 업데이트하는 backward pass(역방향 과정)로 구분할 수 있다. 전체 데이터 셋에 대해 순방향+역방향 과정이 한 번씩 완료되면 1 epoch이 완료되었다고 한다.
Batch size
Total number of training examples present in a single batch.
Batch(배치)의 사전적 의미는 일괄적으로 처리되는 집단이다. 배치는 한 번에 여러개의 데이터를 묶어서 입력하는 것인데, GPU의 병렬 연산 기능을 최대한 효율적으로 사용하기 위해 쓰는 방법이다. 딥러닝 계산 방식은 행렬 연산이므로 1개씩 100번이 아닌 100개씩 1번에 계산할 수 있다. Batch size는 한 번의 배치마다 사용할 데이터의 양을 의미한다.
Iteration
The number of passes to complete one epoch.
Iteration은 1 epoch을 완료하기 위해 학습해야 하는 횟수를 의미한다.
전체 데이터 셋이 1000개일 때 batch size를 10으로 설정하면 1 iteration에 10개의 데이터를 사용하고 100 iteration하면 1 epoch이 완료된다.
Stochastic Gradient Descent
GD의 문제를 해결하기 위한 첫번째 방법으로 Stochastic Gradient Descent(SGD, 확률적 경사하강법)가 있다. SGD는 입력 데이터를 단 한 개만 사용하는 방법이다. 따라서 1 iteration에 걸리는 시간이 짧기 때문에 수렴 속도가 상대적으로 빠르다. 또한 한 개의 데이터를 사용했으므로 아래의 그림처럼 shooting이 발생하여 local minima에 빠질 위험이 적다.
Shooting이 발생해서 더 많은 학습이 필요하지만 1 iteration이 월등히 빠르기 때문에 수렴 속도가 빠르다.
하지만 단점으로는 shooting 때문에 global minimum도 찾지 못 할 가능성이 있으며 GPU의 성능을 전부 활용할 수 없다.
Mini-batch Gradient Descent
GD와 SGD의 장점만을 모은 것이 Mini-batch Gradient Descent(미니배치 경사하강법)이다. SGD가 입력 데이터를 단 한 개 사용했다면 MGD는 여러개 사용한다. 따라서 SGD보다 병렬처리에 유리하며 여전히 shooting이 발생하므로 local minima에 빠질 위험이 적다. 하지만, batch size를 잘 설정해야 하며 SGD보다 메모리 사용량이 높다.
Other Optimizers
GD, SGD, MGD 외에도 여러 optimizer가 있다. 크게 adaptive 계열과 momentum 계열이 있는데 최근에는 두 가지가 혼합된 Adam이 주로 사용된다. 이들은 7강에서 이야기하겠다.