
Best Subset, Forward Stepwise or Lasso? Analysis and Recommendations Based on Extensive Comparisons
10 Mar 2022 | Paper Review
Trevor Hastie, Robert Tibshirani, Ryan Tibshirani가 2020년에 저술한 Best Subset, Forward Stepwise or Lasso? Analysis and Recommendations Based on Extensive Comparisons의 내용을 요약하고, 논문에서 수행한 시뮬레이션을 Julia를 통해 재현하였다.
논문의 목적은 다양한 sparse regression setting에서 $\ell_0$ (best subset selection), $\ell_1$ (Lasso), forward selection 방법들의 상대적인 이점을 비교하는 것이다. 어떤 예측 알고리즘이 최고인가 혹은 어떤 변수 선택 방법이 가장 좋은지에 대한 논문이 아님을 미리 말해두겠다. 이 글의 목적은 논문의 방법들을 간략히 살펴보고, 시뮬레이션 재현 결과를 확인한 후 해석하는 것이다.
해당 논문은 Bertsimas, King, Mazumder가 2016년에 저술한 Best Subset Selection via a Modern Optimization Lens의 후속 논문이므로 이 논문을 먼저 살펴볼 것을 권장한다.
Variable Selection
분석 혹은 예측을 위해 모델을 구축했을 때 다중공선성을 해결하지 못할 경우, 생성한 모델이 타당하다고 할 수 없다. 또한, 모델이 적합하더라도 너무 복잡하면 (이 경우, 변수의 개수가 많은 경우를 의미한다.) 학습 데이터에 대한 성능은 좋을지라도 테스트 데이터에 대한 성능이 좋지 못할 가능성이 높다.
통계학에서는 이러한 문제에 대한 해결책으로 수많은 변수 가운데 특정 변수만을 취하는 변수 선택 (Variable Selection)을 수행한다. 여러 가지 변수 선택 방법을 간단히 짚어보도록 하자. 모든 설명과 예시는 논문에 따라 regression setting 에서 설명하도록 하겠다.
Best Subset Selection
가장 단순한 방법은 best subset selection이다. $p$개의 변수가 있다고 했을 때, 모든 변수를 넣었다 빼보면서 $2^p$개의 모델 중 가장 작은 오차를 가지는 모델을 선택하는 방법이다. 예를 들어, 2개의 변수 $X_1, X_2$가 있다면 아래와 같이 총 $4 = 2^2$가지의 모델을 비교한다.
- Model 1: $Y = \beta_0 + \epsilon$
- Model 2: $Y = \beta_0 + \beta_1 X_1 + \epsilon$
- Model 3: $Y = \beta_0 + \beta_2 X_2 + \epsilon$
- Model 4: $Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \epsilon$
제곱 오차를 사용했을 때 best subset selection 문제를 수식으로 표현하면 다음과 같다.
\[\underset{\beta \in \mathbb{R}^p}{\text{minimize}} ~ \Vert Y - X \beta \Vert_2^2 \quad \text{subject to} \quad \Vert \beta \Vert_0 \le k\]
여기서 $\ell_0$ norm인 $\Vert \beta \Vert_0 = \sum_{i=1}^p 1(\beta_i \neq 0)$은 0이 아닌 계수의 개수를 의미하며, 이는 곧 선택된 변수의 개수와 동일하다. 좀 더 자세히 살펴보면, $k$개 이하의 변수를 가지는 모델 중에서 잔차 제곱합을 최소로 하는 $\beta$를 찾고자 하는 것이다.
변수 선택 방법 중에서 가장 간단한 아이디어인 만큼, 많이 사용할 것 같지만 그렇지 않다. 위의 예시처럼 변수의 개수가 적다면 문제가 되지 않지만, $p$가 커질수록 계산량이 지수적으로 늘어난다. $2^p$가지 모델을 전부 계산하고 잔차 제곱합까지 계산해야 하므로 현실적으로 $p$가 조금만 커져도 현실적으로 계산이 불가능하고 (computationally infeasible), NP hard라고 알려져 있다. 또한, 문제 자체가 non-convex이기 때문에 어려운 문제이기도 하다.
Best subset selection을 계산 가능한 영역으로 가져오려는 시도는 지속적으로 있었다. Bertsimas, King, Mazumder는 2016년 Mixed Integer Optimization (MIO) 방법을 적용한 계산 방법을 제안하였다. 저자들은 해당 방법을 통해 $n$이 천 단위, $p$가 백 단위 혹은 $n$이 백 단위, $p$가 천 단위일 때의 해를 feasible하게 찾을 수 있었다고 한다.
MIO Formulations for the Best Subset Problem
Best subset selection 문제를 다음과 같이 제약조건 하에서의 최적화 형태 (constrained form) 로 바꿔쓸 수 있고,
\[\begin{align*}
\underset{\beta}{\text{minimize}} &\quad \Vert Y - X \beta \Vert_2^2 \\
\text{subject to} &\quad \Vert \beta \Vert_0 \le k
\end{align*}\]
MIO를 적용하여 다시 기술하면, 다음과 같다.
\[\begin{align*}
\underset{\beta, \mathbf{z}}{\text{minimize}} &\quad \Vert Y - X \beta \Vert_2^2 \\
\text{subject to} &\quad \beta_i (1 - z_i) = 0, \quad \forall i = 1, \cdots, p \\
&\quad z_i \in \{0, 1 \}, \quad \forall i = 1, \cdots, p \\
&\quad \sum_{i=1}^p z_i \le k.
\end{align*}\]
좀 더 효율적인 계산을 위해 problem-dependent한 상수 $M_U, M_{\ell}$을 추가하고, 목적함수를 다르게 표현하면 다음을 얻을 수 있다.
\[\begin{align*}
\underset{\beta, \mathbf{z}}{\text{minimize}} &\quad \frac{1}{2} \beta^T(X^TX)\beta - \langle X^TY, \beta \rangle + \frac{1}{2} \Vert Y \Vert_2^2 \\
\text{subject to} &\quad \beta_i (1 - z_i) = 0, \quad \forall i = 1, \cdots, p \\
&\quad z_i \in \{0, 1 \}, \quad \forall i = 1, \cdots, p \\
&\quad \sum_{i=1}^p z_i \le k, \\
&\quad \Vert \beta \Vert_{\infty} \le M_U \quad \text{and} \quad \Vert \beta \Vert_1 \le M_{\ell}
\end{align*}\]
위의 최적화 문제는 warmstart를 적용한 projected gradient 방법을 통해 해를 찾았으며, Gurobi를 사용하였다.
Implementation via Julia
Forward Stepwise Selection
모든 가능한 모델을 탐색하는 best subset selection에 비해 덜 ambitious한 방법이 forward stepwise selection이다. Best subset selection이 computationally infeasible하기 때문에 제시된 대안이라고 생각할 수도 있다. 과정은 다음과 같다.
- 아무 변수도 포함되지 않은 empty model에서 시작한다. 즉, $A_0 = \{ 0 \}$. (0은 절편항을 의미한다.)
-
$k = 1, \dots, \min \{ n, p \}$번째 단계마다 가장 적합한 변수를 하나씩 추가한다.
\[j_k = \underset{j \notin A_{k-1}}{\text{argmin}} ~\Vert Y - P_{A_{k-1} \cup \{ j_k \}} Y \Vert_2^2 \quad \text{and} \quad A_k = A_{k-1} \cup \{ j_k \}\]
여기서 적합하다는 것은 변수를 추가하였을 때 반응변수 $Y$와 상관관계가 가장 높은 것을 의미한다.
Active submatrix $X_{A_{k-1}}$의 QR 분해를 사용하여 변수를 추가하는데, $A_{k-1}$에 아직 포함되지 않은 변수와 $X_{A_{k-1}}$가 직교하도록 만들어주는 과정을 반복하는 과정이 필요하다. 이 때, 계산상의 효율을 위해 modified Gram-Schmidt 방법을 사용한다.
Implementation via Julia
The Lasso
Lasso 문제는 다음과 같이 표현할 수 있다.
\[\underset{\beta \in \mathbb{R}^p}{\text{minimize}} \quad \frac{1}{2} \Vert Y - X \beta \Vert_2^2 + \lambda \Vert \beta \Vert_1, \quad \lambda \ge 0.\]
Lasso 문제는 convex이다. 즉, 이는 $\ell_0$ norm을 사용한 best subset selection 문제를 $\ell_1$ norm을 사용하여 convex relaxation 한 것이라고 생각할 수도 있다.
위 문제를 해결하기 위해 active set strategy와 screening rule을 적용한 pathwise coordinate descent 방법을 이용하였다. 이는 R 패키지 glmnet 에서 lasso의 해를 구하는 방법이다.
Pathwise Coordinate Descent
Hyperparamter $\lambda$를 통해 변수의 개수를 조절할 수 있다. $\lambda$가 커지면 $\lambda \Vert \beta \Vert_1$의 값이 커지므로 $\Vert \beta \Vert_1$ 값이 작아지도록 해를 찾게 되며, 결국 선택되는 변수의 수가 줄어든다 (shrinkage). $\lambda \to \infty$라면 가해진 제약이 너무 강해서 모든 변수가 선택되지 않게 된다. 반대로 $\lambda$가 작아지면 변수를 많이 선택하게 되며, 어느 순간부터는 제약이 없는 상태가 된다. 이 경우 OLS estimator와 동일한 해일 것이다.
Pathwise 방법은 모든 변수가 선택되지 않도록 충분히 큰 $\lambda$를 선택하면서 시작한다. 이 값은
\[\lambda_{\max} = \Vert X^T Y \Vert_{\infty}\]
이며, 이유는 간단하다. 위의 목적함수를 최소화하는 해 $\hat \beta$는 다음의 subgradient condition을 만족해야 하기 때문이다. (페널티 항이 미분불가능하므로 subgradient condition 만족하는지 확인하는 것)
\(\mathbf{x}_j^T(Y - X \hat \beta)+ \lambda s_j = 0, \quad j = 1, \dots, p.\)
$x_j$는 $X$의 $j$번째 열을 나타내며, subgradient $s_j$는 다음과 같다.
\[s_j =
\begin{cases}
\text{sign}(\hat \beta_j) & ,\hat \beta \neq 0 \\
s \in [-1, 1] &, \hat \beta = 0
\end{cases}\]
$\lambda_{\max}$를 선택했다면 $\lambda_{\max}$부터 $\epsilon \lambda_{\max}$까지 log scale로 $K = 100$개의 $\lambda$값을 택한다.
\[\lambda_{\max} = \Vert X^T Y \Vert_{\infty} > \cdots > \lambda_{\min} = \epsilon \lambda_{\max}\]
모든 계수가 0이 되는 $\lambda = \lambda_{\max}$에서 시작하여 $\lambda$값을 조금씩 줄여나간다. 앞서 설명했듯이, 값을 줄이면 변수가 추가로 선택되게 된다. 이때 $k + 1$번째 해 $\hat \beta (\lambda_{k+1})$을 구하기 위해 초기값으로 $k$번째 해 $\hat \beta (\lambda_k)$를 사용한다. 이전 단계의 해를 이용하여 효율적으로 초기화를 진행하는 것이다.
Coordinate descent는 MM 알고리즘의 일종으로, 다른 좌표들은 고정하고 차례대로 하나의 좌표씩 업데이트하는 방법이다. 간단한 2차원의 경우, 아래 그림과 같다. $x$축 방향으로 업데이트한 후, $x$값을 고정하고 $y$축 방향으로 업데이트하면서 최소 (혹은 최대)가 되는 지점을 찾는다.
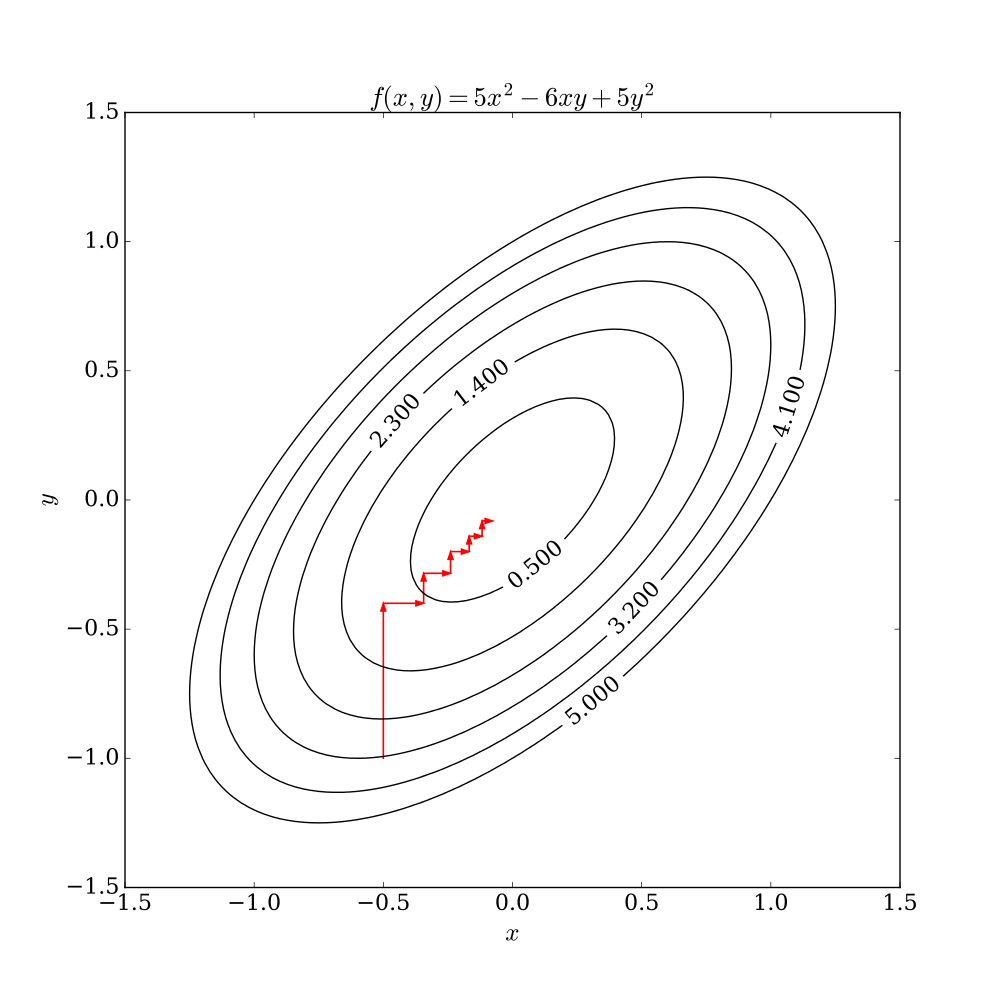 출처 : Wikipedia
출처 : Wikipedia
Coordinate descent를 lasso 문제에 적용하기 위해서는 subgradient condition을 풀어야 한다. 이를 위해, 먼저 $\beta_{-j}$를 $\beta$에서 $j$번째 성분이 없는 벡터로, $X_{-j}$를 design matrix $X$에서 $j$번째 열이 없는 행렬으로 정의하자. 그러면 $X\beta = x_j \beta_j + X_{-j} \beta_{-j}$임을 알 수 있고, 이로부터 다음의 해를 얻을 수 있다. $S_a(x)$는 soft-thresholding 함수이다.
\[\begin{align*}
\lambda s_j &= \mathbf{x}_j^T (Y - \mathbf{x}_j \beta_j - X_{-j} \beta_{-j}) \iff \beta_j = \frac{\mathbf{x}_j^T (Y - X_{-j} \beta_{-j}) - \lambda s_j}{\mathbf{x}_j^T \mathbf{x}_j} \\
\therefore~ \hat{\beta}_j &= S_{\lambda / \Vert \mathbf{x}_j \Vert_2^2} \left( \frac{\mathbf{x}_j^T (Y - X_{-j} \beta_{-j})}{\mathbf{x}_j^T \mathbf{x}_j} \right), \quad \text{where} \quad S_a(x) = \text{sign}(x) (x - a)_+
\end{align*}\]
이를 이용해 lasso 추정량을 찾는 과정은 다음과 같다.
-
초기값을
\[\hat \beta^{(0)} = (\hat \beta^{(0)}_1, \hat \beta^{(0)}_2, \dots, \hat \beta^{(0)}_p)^T \quad \text{and} \quad \lambda = \lambda_{\max}\]
로 설정한다.
- $\hat \beta^{(0)}$에서 $\hat \beta^{(0)}_1$을 제외한 모든 값은 고정하고, $\hat \beta^{(1)}_1$를 계산한다. 즉, $\hat \beta^{(0)} = (\hat \beta^{(1)}_1, \hat \beta^{(0)}_2, \dots, \hat \beta^{(0)}_p)^T$로 업데이트 하는 것.
- $j = 2, \dots, p$ 에 대해서 같은 작업을 반복한다. 모든 $j$에 대해 한 번 씩 업데이트 했다면 $\hat \beta^{(1)} = (\hat \beta^{(1)}_1, \hat \beta^{(1)}_2, \dots, \hat \beta^{(1)}_p)^T$를 구한 것이고, 1 iteration이 수행된 것으로 간주한다.
- 목적함수가 수렴할 때까지 1~3번의 과정을 반복한다.
- $\hat \beta^{(1)}$을 다음 단계의 초기값으로 설정하고, $\lambda$는 $\lambda_{\max}$ 다음 값을 취한다. 모든 $\lambda$에 대하여 1~4번의 과정을 반복하여 solution path를 얻는다.
Active Set Strategy
효율적으로 해를 찾기 위해 active set strategy를 사용한다. 이것은 모든 변수를 다 탐색하는 것이 아니라, active set에 포함된 변수만으로 해를 찾은 뒤 실제 해가 맞는지 확인하는 방법이다. $p$가 매우 클 경우, 모든 변수를 탐색하는 것보다 효율적일 것으로 기대된다. $k$번째 단계의 경우, 그 과정은 다음과 같다.
- $\lambda = \lambda_k$로 설정하고, 초기값은 이전 단계의 해를 사용한다.
- 모든 $p$개의 변수에 대하여 한 번 (혹은 조금 더) coordinate descent를 수행한다.
- 변수 중 0이 아닌 계수를 가지는 변수를 active set $A$로 저장한다.
- Active set $A$에 속한 변수만으로 coordinate descent를 수행하고 해를 찾는다.
-
해가 KKT 조건을 만족하는지 확인하기 위해 다음을 확인한다.
\[\begin{align*}
|\langle \mathbf{x}_j, Y - X \hat \beta(\lambda) \rangle| = \lambda &\quad \text{for all members of the active set,} \\
|\langle \mathbf{x}_j, Y - X \hat \beta(\lambda) \rangle| \le \lambda &\quad \text{for all variables not in the active set.}
\end{align*}\]
만약 조건을 만족하지 않는 변수가 있다면, 그것을 $A$에 추가하고 1~5번의 과정을 반복한다.
Screening Rule
Screening rule은 active set strategy를 사용하기 전에 한 번 더 강한 가정을 부여해서 변수를 걸러내는 과정이다. 구체적인 내용은 Tibshirani가 2012년에 저술한 Strong Rules for Discarding Predictors in Lasso-type Problems을 참고하길 바란다.
Implementation via Julia
Active set strategy와 screening rule를 적용하고 pathwise하게 해를 구하는 것이 논문 구현에 사용된 코드이지만, 너무 길고 복잡해서 coordinate descent 부분만 보여주고자 한다. Coordinate descent를 이용하여 lasso 문제의 해를 구하는 과정을 Julia를 통해 작성한 코드이다.
The Relaxed Lasso
Lasso 추정량과 더불어 (simplified) relaxed lasso (Meinshausen, 2007) 를 고려하였다. $\hat \beta^{\text{lasso}} (\lambda)$를 lasso 추정량이라고 하고, $A_{\lambda}$를 $\hat \beta^{\text{lasso}} (\lambda)$의 active set 이라고 하자. 그러면 $A_{\lambda}$에 포함된 변수만 포함한 $X_{A_{\lambda}}$를 design matrix로 하여 최소제곱 추정량 $\hat \beta_{A_{\lambda}}^{\text{LS}}$를 얻을 수 있다. $A_{\lambda}$에 포함되지 않았던 변수들의 계수를 0으로 하면 full-sized (p-dimensional) 최소제곱 추정량 $\hat \beta^{\text{LS}} (\lambda)$ 을 얻는다.
\[\hat \beta^{\text{lasso}} (\lambda) \longrightarrow A_{\lambda} \longrightarrow \hat \beta^{\text{LS}}_{A_{\lambda}} \overset{\text{padding}}{\longrightarrow} \hat \beta^{\text{LS}} (\lambda)\]
이렇게 얻은 최소제곱 추정량과 lasso 추정량을 weighted sum 한 것이 relaxed lasso 추정량이다.
\[\hat \beta^{\text{relax}} (\lambda, \gamma) = \gamma \hat \beta^{\text{lasso}} (\lambda) + (1 - \gamma) \hat \beta^{\text{LS}} (\lambda)\]
$\lambda$는 기존의 hyperparameter 이며, $\gamma$는 0과 1사이의 값이다. Relaxed lasso 추정량을 구할 때에는 $\lambda$와 $\gamma$를 각각 바꾸어가며 해를 찾는다.
Trevor Hastie, Robert Tibshirani, Ryan Tibshirani가 2020년에 저술한 Best Subset, Forward Stepwise or Lasso? Analysis and Recommendations Based on Extensive Comparisons의 내용을 요약하고, 논문에서 수행한 시뮬레이션을 Julia를 통해 재현하였다.
논문의 목적은 다양한 sparse regression setting에서 $\ell_0$ (best subset selection), $\ell_1$ (Lasso), forward selection 방법들의 상대적인 이점을 비교하는 것이다. 어떤 예측 알고리즘이 최고인가 혹은 어떤 변수 선택 방법이 가장 좋은지에 대한 논문이 아님을 미리 말해두겠다. 이 글의 목적은 논문의 방법들을 간략히 살펴보고, 시뮬레이션 재현 결과를 확인한 후 해석하는 것이다.
해당 논문은 Bertsimas, King, Mazumder가 2016년에 저술한 Best Subset Selection via a Modern Optimization Lens의 후속 논문이므로 이 논문을 먼저 살펴볼 것을 권장한다.
Variable Selection
분석 혹은 예측을 위해 모델을 구축했을 때 다중공선성을 해결하지 못할 경우, 생성한 모델이 타당하다고 할 수 없다. 또한, 모델이 적합하더라도 너무 복잡하면 (이 경우, 변수의 개수가 많은 경우를 의미한다.) 학습 데이터에 대한 성능은 좋을지라도 테스트 데이터에 대한 성능이 좋지 못할 가능성이 높다. 통계학에서는 이러한 문제에 대한 해결책으로 수많은 변수 가운데 특정 변수만을 취하는 변수 선택 (Variable Selection)을 수행한다. 여러 가지 변수 선택 방법을 간단히 짚어보도록 하자. 모든 설명과 예시는 논문에 따라 regression setting 에서 설명하도록 하겠다.
Best Subset Selection
가장 단순한 방법은 best subset selection이다. $p$개의 변수가 있다고 했을 때, 모든 변수를 넣었다 빼보면서 $2^p$개의 모델 중 가장 작은 오차를 가지는 모델을 선택하는 방법이다. 예를 들어, 2개의 변수 $X_1, X_2$가 있다면 아래와 같이 총 $4 = 2^2$가지의 모델을 비교한다.
- Model 1: $Y = \beta_0 + \epsilon$
- Model 2: $Y = \beta_0 + \beta_1 X_1 + \epsilon$
- Model 3: $Y = \beta_0 + \beta_2 X_2 + \epsilon$
- Model 4: $Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \epsilon$
제곱 오차를 사용했을 때 best subset selection 문제를 수식으로 표현하면 다음과 같다.
\[\underset{\beta \in \mathbb{R}^p}{\text{minimize}} ~ \Vert Y - X \beta \Vert_2^2 \quad \text{subject to} \quad \Vert \beta \Vert_0 \le k\]여기서 $\ell_0$ norm인 $\Vert \beta \Vert_0 = \sum_{i=1}^p 1(\beta_i \neq 0)$은 0이 아닌 계수의 개수를 의미하며, 이는 곧 선택된 변수의 개수와 동일하다. 좀 더 자세히 살펴보면, $k$개 이하의 변수를 가지는 모델 중에서 잔차 제곱합을 최소로 하는 $\beta$를 찾고자 하는 것이다.
변수 선택 방법 중에서 가장 간단한 아이디어인 만큼, 많이 사용할 것 같지만 그렇지 않다. 위의 예시처럼 변수의 개수가 적다면 문제가 되지 않지만, $p$가 커질수록 계산량이 지수적으로 늘어난다. $2^p$가지 모델을 전부 계산하고 잔차 제곱합까지 계산해야 하므로 현실적으로 $p$가 조금만 커져도 현실적으로 계산이 불가능하고 (computationally infeasible), NP hard라고 알려져 있다. 또한, 문제 자체가 non-convex이기 때문에 어려운 문제이기도 하다.
Best subset selection을 계산 가능한 영역으로 가져오려는 시도는 지속적으로 있었다. Bertsimas, King, Mazumder는 2016년 Mixed Integer Optimization (MIO) 방법을 적용한 계산 방법을 제안하였다. 저자들은 해당 방법을 통해 $n$이 천 단위, $p$가 백 단위 혹은 $n$이 백 단위, $p$가 천 단위일 때의 해를 feasible하게 찾을 수 있었다고 한다.
MIO Formulations for the Best Subset Problem
Best subset selection 문제를 다음과 같이 제약조건 하에서의 최적화 형태 (constrained form) 로 바꿔쓸 수 있고,
\[\begin{align*} \underset{\beta}{\text{minimize}} &\quad \Vert Y - X \beta \Vert_2^2 \\ \text{subject to} &\quad \Vert \beta \Vert_0 \le k \end{align*}\]MIO를 적용하여 다시 기술하면, 다음과 같다.
\[\begin{align*} \underset{\beta, \mathbf{z}}{\text{minimize}} &\quad \Vert Y - X \beta \Vert_2^2 \\ \text{subject to} &\quad \beta_i (1 - z_i) = 0, \quad \forall i = 1, \cdots, p \\ &\quad z_i \in \{0, 1 \}, \quad \forall i = 1, \cdots, p \\ &\quad \sum_{i=1}^p z_i \le k. \end{align*}\]좀 더 효율적인 계산을 위해 problem-dependent한 상수 $M_U, M_{\ell}$을 추가하고, 목적함수를 다르게 표현하면 다음을 얻을 수 있다.
\[\begin{align*} \underset{\beta, \mathbf{z}}{\text{minimize}} &\quad \frac{1}{2} \beta^T(X^TX)\beta - \langle X^TY, \beta \rangle + \frac{1}{2} \Vert Y \Vert_2^2 \\ \text{subject to} &\quad \beta_i (1 - z_i) = 0, \quad \forall i = 1, \cdots, p \\ &\quad z_i \in \{0, 1 \}, \quad \forall i = 1, \cdots, p \\ &\quad \sum_{i=1}^p z_i \le k, \\ &\quad \Vert \beta \Vert_{\infty} \le M_U \quad \text{and} \quad \Vert \beta \Vert_1 \le M_{\ell} \end{align*}\]위의 최적화 문제는 warmstart를 적용한 projected gradient 방법을 통해 해를 찾았으며, Gurobi를 사용하였다.
Implementation via Julia
Forward Stepwise Selection
모든 가능한 모델을 탐색하는 best subset selection에 비해 덜 ambitious한 방법이 forward stepwise selection이다. Best subset selection이 computationally infeasible하기 때문에 제시된 대안이라고 생각할 수도 있다. 과정은 다음과 같다.
- 아무 변수도 포함되지 않은 empty model에서 시작한다. 즉, $A_0 = \{ 0 \}$. (0은 절편항을 의미한다.)
-
$k = 1, \dots, \min \{ n, p \}$번째 단계마다 가장 적합한 변수를 하나씩 추가한다.
\[j_k = \underset{j \notin A_{k-1}}{\text{argmin}} ~\Vert Y - P_{A_{k-1} \cup \{ j_k \}} Y \Vert_2^2 \quad \text{and} \quad A_k = A_{k-1} \cup \{ j_k \}\]여기서 적합하다는 것은 변수를 추가하였을 때 반응변수 $Y$와 상관관계가 가장 높은 것을 의미한다.
Active submatrix $X_{A_{k-1}}$의 QR 분해를 사용하여 변수를 추가하는데, $A_{k-1}$에 아직 포함되지 않은 변수와 $X_{A_{k-1}}$가 직교하도록 만들어주는 과정을 반복하는 과정이 필요하다. 이 때, 계산상의 효율을 위해 modified Gram-Schmidt 방법을 사용한다.
Implementation via Julia
The Lasso
Lasso 문제는 다음과 같이 표현할 수 있다.
\[\underset{\beta \in \mathbb{R}^p}{\text{minimize}} \quad \frac{1}{2} \Vert Y - X \beta \Vert_2^2 + \lambda \Vert \beta \Vert_1, \quad \lambda \ge 0.\]Lasso 문제는 convex이다. 즉, 이는 $\ell_0$ norm을 사용한 best subset selection 문제를 $\ell_1$ norm을 사용하여 convex relaxation 한 것이라고 생각할 수도 있다.
위 문제를 해결하기 위해 active set strategy와 screening rule을 적용한 pathwise coordinate descent 방법을 이용하였다. 이는 R 패키지 glmnet 에서 lasso의 해를 구하는 방법이다.
Pathwise Coordinate Descent
Hyperparamter $\lambda$를 통해 변수의 개수를 조절할 수 있다. $\lambda$가 커지면 $\lambda \Vert \beta \Vert_1$의 값이 커지므로 $\Vert \beta \Vert_1$ 값이 작아지도록 해를 찾게 되며, 결국 선택되는 변수의 수가 줄어든다 (shrinkage). $\lambda \to \infty$라면 가해진 제약이 너무 강해서 모든 변수가 선택되지 않게 된다. 반대로 $\lambda$가 작아지면 변수를 많이 선택하게 되며, 어느 순간부터는 제약이 없는 상태가 된다. 이 경우 OLS estimator와 동일한 해일 것이다.
Pathwise 방법은 모든 변수가 선택되지 않도록 충분히 큰 $\lambda$를 선택하면서 시작한다. 이 값은
\[\lambda_{\max} = \Vert X^T Y \Vert_{\infty}\]이며, 이유는 간단하다. 위의 목적함수를 최소화하는 해 $\hat \beta$는 다음의 subgradient condition을 만족해야 하기 때문이다. (페널티 항이 미분불가능하므로 subgradient condition 만족하는지 확인하는 것)
\(\mathbf{x}_j^T(Y - X \hat \beta)+ \lambda s_j = 0, \quad j = 1, \dots, p.\) $x_j$는 $X$의 $j$번째 열을 나타내며, subgradient $s_j$는 다음과 같다.
\[s_j = \begin{cases} \text{sign}(\hat \beta_j) & ,\hat \beta \neq 0 \\ s \in [-1, 1] &, \hat \beta = 0 \end{cases}\]$\lambda_{\max}$를 선택했다면 $\lambda_{\max}$부터 $\epsilon \lambda_{\max}$까지 log scale로 $K = 100$개의 $\lambda$값을 택한다.
\[\lambda_{\max} = \Vert X^T Y \Vert_{\infty} > \cdots > \lambda_{\min} = \epsilon \lambda_{\max}\]모든 계수가 0이 되는 $\lambda = \lambda_{\max}$에서 시작하여 $\lambda$값을 조금씩 줄여나간다. 앞서 설명했듯이, 값을 줄이면 변수가 추가로 선택되게 된다. 이때 $k + 1$번째 해 $\hat \beta (\lambda_{k+1})$을 구하기 위해 초기값으로 $k$번째 해 $\hat \beta (\lambda_k)$를 사용한다. 이전 단계의 해를 이용하여 효율적으로 초기화를 진행하는 것이다.
Coordinate descent는 MM 알고리즘의 일종으로, 다른 좌표들은 고정하고 차례대로 하나의 좌표씩 업데이트하는 방법이다. 간단한 2차원의 경우, 아래 그림과 같다. $x$축 방향으로 업데이트한 후, $x$값을 고정하고 $y$축 방향으로 업데이트하면서 최소 (혹은 최대)가 되는 지점을 찾는다.
출처 : Wikipedia
Coordinate descent를 lasso 문제에 적용하기 위해서는 subgradient condition을 풀어야 한다. 이를 위해, 먼저 $\beta_{-j}$를 $\beta$에서 $j$번째 성분이 없는 벡터로, $X_{-j}$를 design matrix $X$에서 $j$번째 열이 없는 행렬으로 정의하자. 그러면 $X\beta = x_j \beta_j + X_{-j} \beta_{-j}$임을 알 수 있고, 이로부터 다음의 해를 얻을 수 있다. $S_a(x)$는 soft-thresholding 함수이다.
\[\begin{align*} \lambda s_j &= \mathbf{x}_j^T (Y - \mathbf{x}_j \beta_j - X_{-j} \beta_{-j}) \iff \beta_j = \frac{\mathbf{x}_j^T (Y - X_{-j} \beta_{-j}) - \lambda s_j}{\mathbf{x}_j^T \mathbf{x}_j} \\ \therefore~ \hat{\beta}_j &= S_{\lambda / \Vert \mathbf{x}_j \Vert_2^2} \left( \frac{\mathbf{x}_j^T (Y - X_{-j} \beta_{-j})}{\mathbf{x}_j^T \mathbf{x}_j} \right), \quad \text{where} \quad S_a(x) = \text{sign}(x) (x - a)_+ \end{align*}\]이를 이용해 lasso 추정량을 찾는 과정은 다음과 같다.
-
초기값을
\[\hat \beta^{(0)} = (\hat \beta^{(0)}_1, \hat \beta^{(0)}_2, \dots, \hat \beta^{(0)}_p)^T \quad \text{and} \quad \lambda = \lambda_{\max}\]로 설정한다.
- $\hat \beta^{(0)}$에서 $\hat \beta^{(0)}_1$을 제외한 모든 값은 고정하고, $\hat \beta^{(1)}_1$를 계산한다. 즉, $\hat \beta^{(0)} = (\hat \beta^{(1)}_1, \hat \beta^{(0)}_2, \dots, \hat \beta^{(0)}_p)^T$로 업데이트 하는 것.
- $j = 2, \dots, p$ 에 대해서 같은 작업을 반복한다. 모든 $j$에 대해 한 번 씩 업데이트 했다면 $\hat \beta^{(1)} = (\hat \beta^{(1)}_1, \hat \beta^{(1)}_2, \dots, \hat \beta^{(1)}_p)^T$를 구한 것이고, 1 iteration이 수행된 것으로 간주한다.
- 목적함수가 수렴할 때까지 1~3번의 과정을 반복한다.
- $\hat \beta^{(1)}$을 다음 단계의 초기값으로 설정하고, $\lambda$는 $\lambda_{\max}$ 다음 값을 취한다. 모든 $\lambda$에 대하여 1~4번의 과정을 반복하여 solution path를 얻는다.
Active Set Strategy
효율적으로 해를 찾기 위해 active set strategy를 사용한다. 이것은 모든 변수를 다 탐색하는 것이 아니라, active set에 포함된 변수만으로 해를 찾은 뒤 실제 해가 맞는지 확인하는 방법이다. $p$가 매우 클 경우, 모든 변수를 탐색하는 것보다 효율적일 것으로 기대된다. $k$번째 단계의 경우, 그 과정은 다음과 같다.
- $\lambda = \lambda_k$로 설정하고, 초기값은 이전 단계의 해를 사용한다.
- 모든 $p$개의 변수에 대하여 한 번 (혹은 조금 더) coordinate descent를 수행한다.
- 변수 중 0이 아닌 계수를 가지는 변수를 active set $A$로 저장한다.
- Active set $A$에 속한 변수만으로 coordinate descent를 수행하고 해를 찾는다.
-
해가 KKT 조건을 만족하는지 확인하기 위해 다음을 확인한다.
\[\begin{align*} |\langle \mathbf{x}_j, Y - X \hat \beta(\lambda) \rangle| = \lambda &\quad \text{for all members of the active set,} \\ |\langle \mathbf{x}_j, Y - X \hat \beta(\lambda) \rangle| \le \lambda &\quad \text{for all variables not in the active set.} \end{align*}\]만약 조건을 만족하지 않는 변수가 있다면, 그것을 $A$에 추가하고 1~5번의 과정을 반복한다.
Screening Rule
Screening rule은 active set strategy를 사용하기 전에 한 번 더 강한 가정을 부여해서 변수를 걸러내는 과정이다. 구체적인 내용은 Tibshirani가 2012년에 저술한 Strong Rules for Discarding Predictors in Lasso-type Problems을 참고하길 바란다.
Implementation via Julia
Active set strategy와 screening rule를 적용하고 pathwise하게 해를 구하는 것이 논문 구현에 사용된 코드이지만, 너무 길고 복잡해서 coordinate descent 부분만 보여주고자 한다. Coordinate descent를 이용하여 lasso 문제의 해를 구하는 과정을 Julia를 통해 작성한 코드이다.
The Relaxed Lasso
Lasso 추정량과 더불어 (simplified) relaxed lasso (Meinshausen, 2007) 를 고려하였다. $\hat \beta^{\text{lasso}} (\lambda)$를 lasso 추정량이라고 하고, $A_{\lambda}$를 $\hat \beta^{\text{lasso}} (\lambda)$의 active set 이라고 하자. 그러면 $A_{\lambda}$에 포함된 변수만 포함한 $X_{A_{\lambda}}$를 design matrix로 하여 최소제곱 추정량 $\hat \beta_{A_{\lambda}}^{\text{LS}}$를 얻을 수 있다. $A_{\lambda}$에 포함되지 않았던 변수들의 계수를 0으로 하면 full-sized (p-dimensional) 최소제곱 추정량 $\hat \beta^{\text{LS}} (\lambda)$ 을 얻는다.
\[\hat \beta^{\text{lasso}} (\lambda) \longrightarrow A_{\lambda} \longrightarrow \hat \beta^{\text{LS}}_{A_{\lambda}} \overset{\text{padding}}{\longrightarrow} \hat \beta^{\text{LS}} (\lambda)\]이렇게 얻은 최소제곱 추정량과 lasso 추정량을 weighted sum 한 것이 relaxed lasso 추정량이다.
\[\hat \beta^{\text{relax}} (\lambda, \gamma) = \gamma \hat \beta^{\text{lasso}} (\lambda) + (1 - \gamma) \hat \beta^{\text{LS}} (\lambda)\]$\lambda$는 기존의 hyperparameter 이며, $\gamma$는 0과 1사이의 값이다. Relaxed lasso 추정량을 구할 때에는 $\lambda$와 $\gamma$를 각각 바꾸어가며 해를 찾는다.