
[CS231n]Lecture 6-Training Neural Networks, Part 1 - 2nd
08 Jul 2021 | CS231n
지난 포스트와 이어지는 내용입니다. Data preprocessing과 weight initialization에 대해 다룹니다.
Data Preprocessing
모델을 적합하기 위해 데이터를 사전 처리를 하는 과정이다. 데이터 사전 처리 과정은 크게 데이터 엔지니어링과 특성 추출로 나눌 수 있다. 아래의 flow에서 각각 첫 번째와 두 번째 화살표에 해당하는 과정이다. 물론 데이터에 따라 과정의 순서가 바뀌거나 생략될 수 있다. 절대적인 방법은 없기 때문에 올바른 사전 처리를 위해 경험적 지식이 요구된다.
Raw Data -> Prepared Data -> Engineered Features -> Model Fitting
사전 처리 작업
사전 처리 과정은 매우 다양하기 때문에 모든 과정을 소개할 수 없다. 따라서 대체로 많이 하는 과정들을 추려서 소개하려고 한다.
프로그래밍을 공부할 때 등장하는 toy data와 달리 실제 분석에서의 데이터는 그닥 친절하지 않다. 대표적으로 다음과 같은 문제가 있다.
-
Missing values : 결측치를 처리하지 않고 분석에 사용하면 분석 결과를 신뢰하기 어렵다. 정확도 또한 현저히 떨어질 수 있다. 따라서 적절한 imputation 과정이나 데이터 삭제 등을 통해 처리해 주어야 한다. 그런데 결측치를 처리하기 힘들다고 해서 마음대로 데이터를 삭제하면 안 된다.
-
Centering and Standardizing : 데이터 내 설명변수의 단위가 제각각인 경우 분석에 영향을 줄 수 있다. 예를 들어, 자료 내 거리 정보를 포함하는 변수가 여러가지인 경우를 생각해보자. 변수1은 단위가 cm이고 변수2는 단위가 km라면 변수1의 한 단위(1 unit)만큼의 변화보다 변수2의 한 단위만큼의 변화가 훨씬 더 많은 영향을 줄 수 밖에 없다. 이러한 경우, 평균을 빼는 centering과 표준편차로 나누어주는 standardizing이 필요하다. Scale이 같아진다는 장점이 있지만, 해석이 어려워질 수도 있기 때문에 이 과정도 무작정 해서는 안 된다. 필요에 따라 둘 중 하나만 수행하기도 한다.
-
Partitioning Data : Cross validation(교차 검증)을 위해 필요한 작업이다. 교차 검증에 대한 내용을 소개하지는 않겠지만, 모델의 정확도와 신뢰도를 위해 반드시 수행해야 한다.
-
Transforming Data : 원시 데이터가 우리가 원하는 대로 변수들이 정렬되어 있으면 좋겠지만, 그렇지 않다면 포맷을 변환해야 한다. 정렬, 병합, 축 변환 등의 작업을 포함한다.
-
Feature Engineering : 간단히 말해서 필요없는 변수를 제거하거나 새로운 변수를 생성하는 작업이다. 변수가 많을수록 모델의 정확도는 향상되지만, 과적합(overfitting)의 가능성이 있기 때문에 필요 없는 변수는 제거해야 한다. 혹은 변수 간 상관관계가 강한 경우에도 제거한다.
변수 간 상관관계가 강하거나 변수가 너무 많은 경우, PCA 등의 차원 축소 기법들을 이용하기도 한다. 이외에도 분석자가 판단하기에 적절한 변수를 만드는 과정도 전부 포함된다. 모델의 성능을 결정 짓는 매우 중요한 과정이기 때문에 신중하게 작업해야 한다. EDA와 병행하면 좋다.
더미 변수 생성 혹은 비정형 데이터의 임베딩(ex. one-hot encoding)도 여기에 포함된다.
Weight Initialization
파라미터의 초기값을 어떻게 설정하느냐에 따라 학습의 결과가 많이 달라진다. 여러 케이스를 살펴보면서 효율적인 초기화에 대해 알아보자.
What happens when $W=0$ is used?
가장 먼저 살펴볼 케이스는 모든 파라미터의 초기값을 0으로 설정하는 경우이다. 이는 직관적으로도 효율적이지 않다는 것을 알 수 있다. 구체적으로는 다음과 같은 두 가지 문제가 발생한다. 첫째, 초기값이 0이기 때문에 모든 뉴런이 같은 역할을 하게 된다. 둘째, 모든 뉴런이 같은 역할을 하기 때문에 gradient 값이 전부 같아진다. 주의할 점은 모든 뉴런이 같은 역할을 할 뿐이지 죽어버리는 것은 아니다.
Small random numbers
두 번째 아이디어는 평균이 0이고, 표준편차가 매우 작은 정규분포에서 값을 취해 초기화하는 것이다. 코드를 통해 구현해보고 결과를 살펴보자. 강의 자료의 코드는 python2여서 python3로 변경하였다.
import numpy as np
from matplotlib import pyplot as plt
D = np.random.randn(1000, 500)
hidden_layer_sizes = [500]*10 # 10-layer net with 500 neurons on each layer
nonlinearities = ['tanh']*len(hidden_layer_sizes) # using tanh non-linearities
act = {'relu' : lambda x : np.maximum(0,x), 'tanh' : lambda x : np.tanh(x)}
Hs = {}
for i in range(len(hidden_layer_sizes)):
X = D if i == 0 else Hs[i-1] # input at this layer
fan_in = X.shape[1]
fan_out = hidden_layer_sizes[i]
W = np.random.randn(fan_in, fan_out)*0.01 # layer initialization
H = np.dot(X,W)
H = act[nonlinearities[i]](H)
Hs[i] = H
print("input layer had mean %f and std %f" % (np.mean(D), np.std(D)))
layer_means = [np.mean(H) for i,H in Hs.items()]
layer_stds = [np.std(H) for i,H in Hs.items()]
for i,H in Hs.items():
print("hidden layer %d had mean %f and std %f" % (i+1, layer_means[i], layer_stds[i]))
# plot the means and standard deviations
plt.figure(figsize=(14,5))
plt.subplot(121)
plt.plot(Hs.keys(), layer_means, 'ob-')
plt.title('layer mean')
plt.subplot(122)
plt.plot(Hs.keys(),layer_stds, 'or-')
plt.title('layer std')
# plot the raw distributions
plt.figure(figsize=(15,5))
for i,H in Hs.items():
plt.subplot(1, len(Hs), i+1)
plt.hist(H.ravel(), 50, range=(-1,1))
500개의 뉴런을 가진 layer가 10개 있으며 초기값을 0으로 설정해주었다. 먼저 각 layer의 평균과 표준편차를 구하면 다음과 같다.
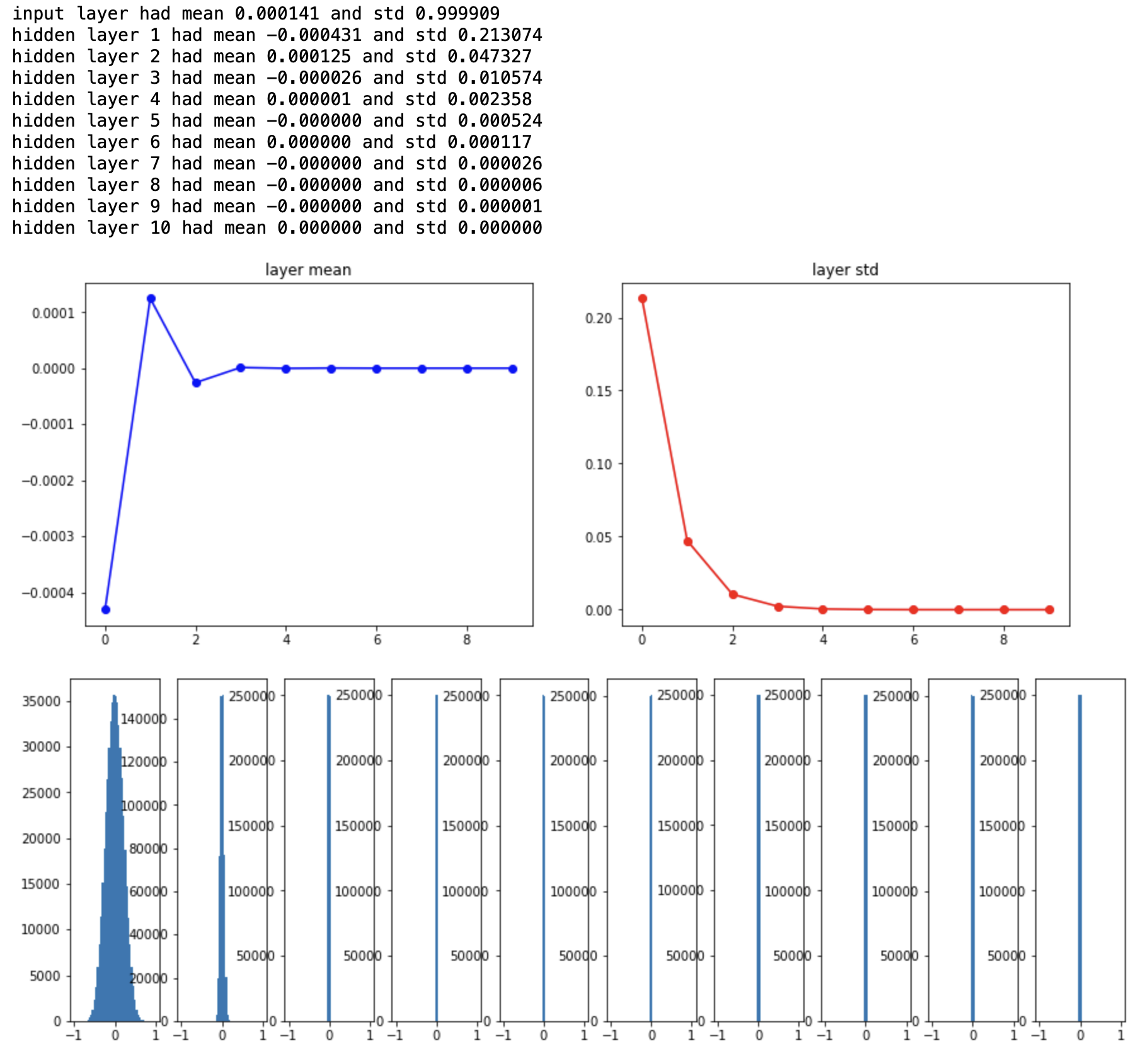
뒤쪽 layer로 갈수록 표준편차가 점점 작아지다가 결국 평균과 표준편차가 모두 0이 되어버린다. 모든 activation이 0이 되어버렸으므로, vanishing gradient 현상이 발생한다. 이러한 초기화 방법은 데이터의 size가 작거나 적은 layer를 사용하면 큰 문제가 없지만, 지금처럼 데이터의 양이 조금만 많아져도 모든 뉴런이 같은 역할을 하게 되어버린다. 굳이 여러 layer를 쌓을 필요가 없는 것이다.
이번에는 표준편차를 크게 했을 때 어떤 변화가 있을지 알아보자. 아래의 초기화 부분을 제외하면 위의 코드와 동일하다.
W = np.random.randn(fan_in, fan_out)*1.0
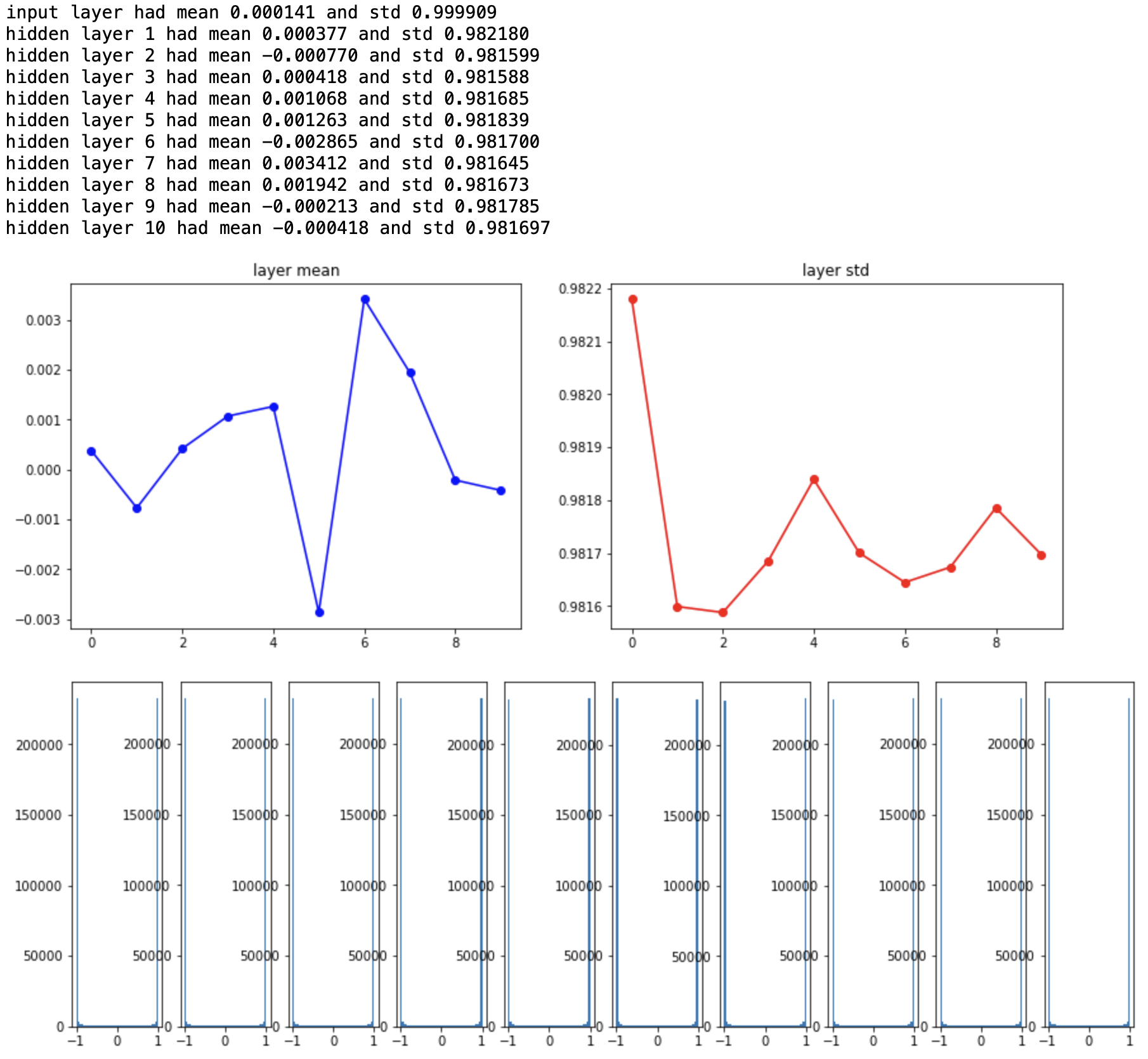
앞선 케이스와는 정반대의 양상을 보여준다. 표준편차가 너무 커서 대부분의 뉴런이 -1과 1의 값만을 가지게 되는 saturation 현상이 발생하고 모든 gradient가 0이 되어버린다.
Reasonable Initialization
결국 우리는 layer를 늘리더라도 saturation되지 않는 범위 내에서 layer의 평균과 표준편차를 일정하게 유지하기를 원한다. 이러한 결과를 얻기 위한 방안으로 분산 조정 기반 초기화 방법이 제시되었다.
Xavier Initialization
Xavier initialization은 입력값과 출력값의 차원을 고려하여 분산을 결정하는 초기화 방법으로 모든 layer마다 분산을 다르게 적용할 수 있다. 구체적인 수식은 다음과 같다. 입력값과 출력값의 차원이 같다면 오른쪽 수식처럼 간단해진다.
\[Var(W) = \frac{2}{n_{in} + n_{out}} \text{ or } \frac{1}{n_{in}}\]
W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in) # assume same sizes
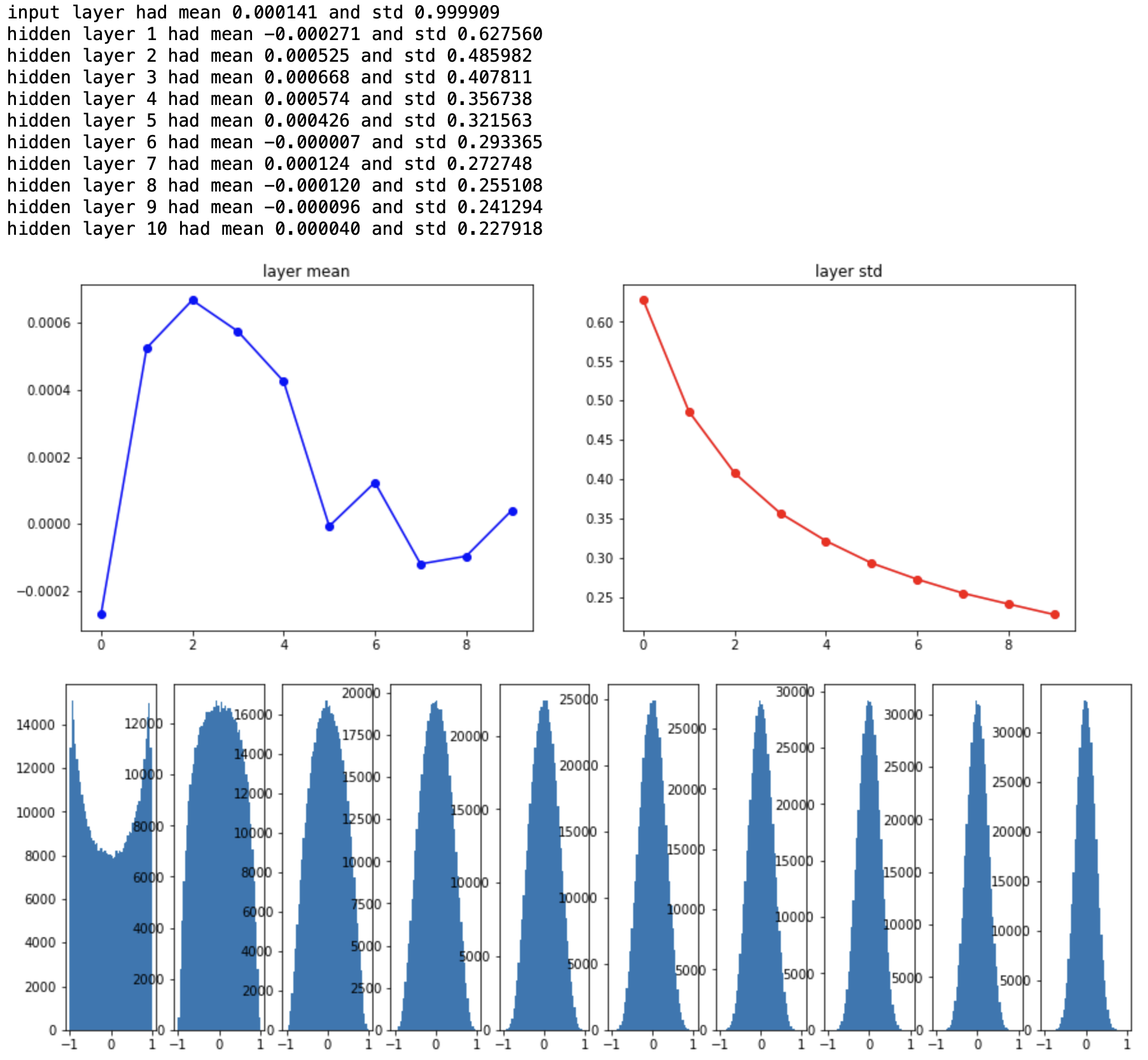
실험 결과 뒤쪽 layer에서도 activation이 고르게 분포되어 있음을 알 수 있다. 하지만 Xavier initialization이 만능은 아니다. ReLU 활성함수를 사용하면 음의 값은 전부 0으로 출력되기 때문에 앞선 케이스와 비슷한 좋지 않은 결과가 발생한다.
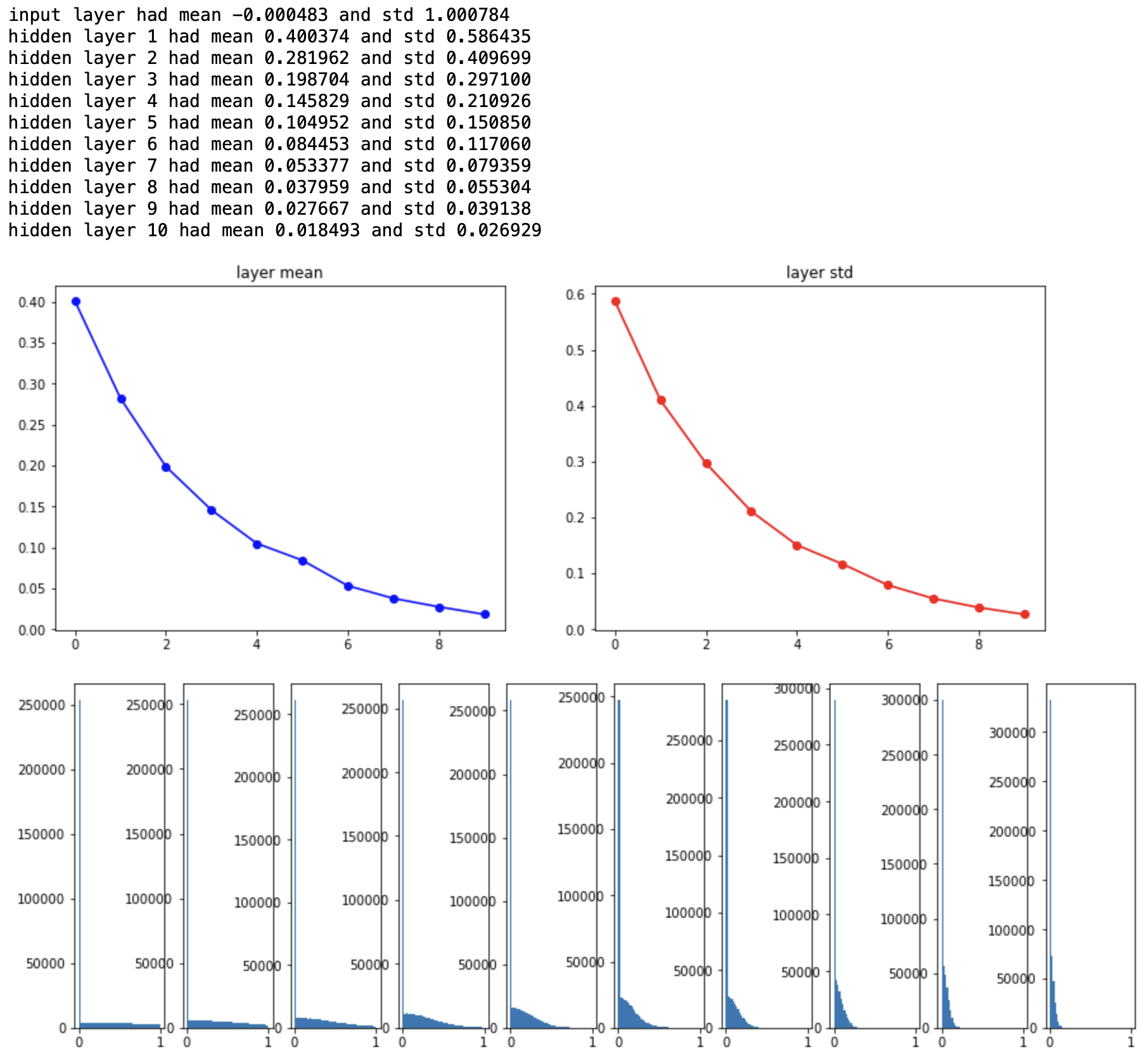
He Initialization
Xavier initialization의 문제점을 보완하기 위해 제시된 방안으로 He initialization이 있다. 이는 입력값의 차원만을 고려한 것으로서 주로 ReLU 활성함수를 사용할 때 함께 사용한다.
\[Var(W) = \frac{2}{n_{in}}\]
W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in/2) # assume same sizes
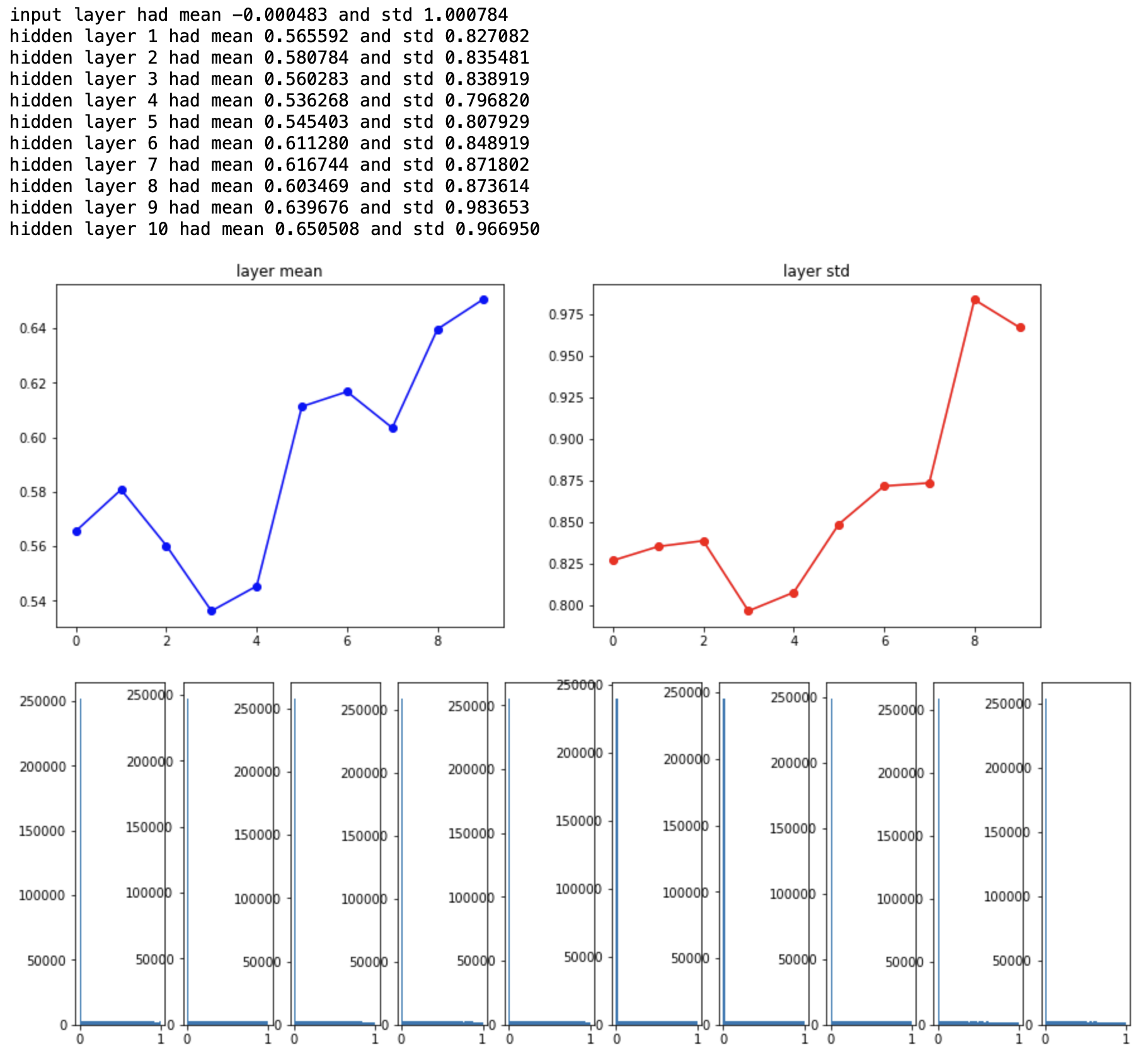
activation이 다시 고르게 분포되어 있음을 확인할 수 있다. 요약하자면 ReLU 계열은 He 초기화를, 나머지는 Xavier 초기화를 사용하면 된다. 이 분야는 지금도 활발하게 연구되고 있기 때문에 최신 동향을 살펴가며 알맞은 초기화 기법을 사용하면 좋을 것 같다.
Further Reading
지난 포스트와 이어지는 내용입니다. Data preprocessing과 weight initialization에 대해 다룹니다.
Data Preprocessing
모델을 적합하기 위해 데이터를 사전 처리를 하는 과정이다. 데이터 사전 처리 과정은 크게 데이터 엔지니어링과 특성 추출로 나눌 수 있다. 아래의 flow에서 각각 첫 번째와 두 번째 화살표에 해당하는 과정이다. 물론 데이터에 따라 과정의 순서가 바뀌거나 생략될 수 있다. 절대적인 방법은 없기 때문에 올바른 사전 처리를 위해 경험적 지식이 요구된다.
Raw Data -> Prepared Data -> Engineered Features -> Model Fitting
사전 처리 작업
사전 처리 과정은 매우 다양하기 때문에 모든 과정을 소개할 수 없다. 따라서 대체로 많이 하는 과정들을 추려서 소개하려고 한다.
프로그래밍을 공부할 때 등장하는 toy data와 달리 실제 분석에서의 데이터는 그닥 친절하지 않다. 대표적으로 다음과 같은 문제가 있다.
-
Missing values : 결측치를 처리하지 않고 분석에 사용하면 분석 결과를 신뢰하기 어렵다. 정확도 또한 현저히 떨어질 수 있다. 따라서 적절한 imputation 과정이나 데이터 삭제 등을 통해 처리해 주어야 한다. 그런데 결측치를 처리하기 힘들다고 해서 마음대로 데이터를 삭제하면 안 된다.
-
Centering and Standardizing : 데이터 내 설명변수의 단위가 제각각인 경우 분석에 영향을 줄 수 있다. 예를 들어, 자료 내 거리 정보를 포함하는 변수가 여러가지인 경우를 생각해보자. 변수1은 단위가 cm이고 변수2는 단위가 km라면 변수1의 한 단위(1 unit)만큼의 변화보다 변수2의 한 단위만큼의 변화가 훨씬 더 많은 영향을 줄 수 밖에 없다. 이러한 경우, 평균을 빼는 centering과 표준편차로 나누어주는 standardizing이 필요하다. Scale이 같아진다는 장점이 있지만, 해석이 어려워질 수도 있기 때문에 이 과정도 무작정 해서는 안 된다. 필요에 따라 둘 중 하나만 수행하기도 한다.
-
Partitioning Data : Cross validation(교차 검증)을 위해 필요한 작업이다. 교차 검증에 대한 내용을 소개하지는 않겠지만, 모델의 정확도와 신뢰도를 위해 반드시 수행해야 한다.
-
Transforming Data : 원시 데이터가 우리가 원하는 대로 변수들이 정렬되어 있으면 좋겠지만, 그렇지 않다면 포맷을 변환해야 한다. 정렬, 병합, 축 변환 등의 작업을 포함한다.
-
Feature Engineering : 간단히 말해서 필요없는 변수를 제거하거나 새로운 변수를 생성하는 작업이다. 변수가 많을수록 모델의 정확도는 향상되지만, 과적합(overfitting)의 가능성이 있기 때문에 필요 없는 변수는 제거해야 한다. 혹은 변수 간 상관관계가 강한 경우에도 제거한다. 변수 간 상관관계가 강하거나 변수가 너무 많은 경우, PCA 등의 차원 축소 기법들을 이용하기도 한다. 이외에도 분석자가 판단하기에 적절한 변수를 만드는 과정도 전부 포함된다. 모델의 성능을 결정 짓는 매우 중요한 과정이기 때문에 신중하게 작업해야 한다. EDA와 병행하면 좋다. 더미 변수 생성 혹은 비정형 데이터의 임베딩(ex. one-hot encoding)도 여기에 포함된다.
Weight Initialization
파라미터의 초기값을 어떻게 설정하느냐에 따라 학습의 결과가 많이 달라진다. 여러 케이스를 살펴보면서 효율적인 초기화에 대해 알아보자.
What happens when $W=0$ is used?
가장 먼저 살펴볼 케이스는 모든 파라미터의 초기값을 0으로 설정하는 경우이다. 이는 직관적으로도 효율적이지 않다는 것을 알 수 있다. 구체적으로는 다음과 같은 두 가지 문제가 발생한다. 첫째, 초기값이 0이기 때문에 모든 뉴런이 같은 역할을 하게 된다. 둘째, 모든 뉴런이 같은 역할을 하기 때문에 gradient 값이 전부 같아진다. 주의할 점은 모든 뉴런이 같은 역할을 할 뿐이지 죽어버리는 것은 아니다.
Small random numbers
두 번째 아이디어는 평균이 0이고, 표준편차가 매우 작은 정규분포에서 값을 취해 초기화하는 것이다. 코드를 통해 구현해보고 결과를 살펴보자. 강의 자료의 코드는 python2여서 python3로 변경하였다.
import numpy as np
from matplotlib import pyplot as plt
D = np.random.randn(1000, 500)
hidden_layer_sizes = [500]*10 # 10-layer net with 500 neurons on each layer
nonlinearities = ['tanh']*len(hidden_layer_sizes) # using tanh non-linearities
act = {'relu' : lambda x : np.maximum(0,x), 'tanh' : lambda x : np.tanh(x)}
Hs = {}
for i in range(len(hidden_layer_sizes)):
X = D if i == 0 else Hs[i-1] # input at this layer
fan_in = X.shape[1]
fan_out = hidden_layer_sizes[i]
W = np.random.randn(fan_in, fan_out)*0.01 # layer initialization
H = np.dot(X,W)
H = act[nonlinearities[i]](H)
Hs[i] = H
print("input layer had mean %f and std %f" % (np.mean(D), np.std(D)))
layer_means = [np.mean(H) for i,H in Hs.items()]
layer_stds = [np.std(H) for i,H in Hs.items()]
for i,H in Hs.items():
print("hidden layer %d had mean %f and std %f" % (i+1, layer_means[i], layer_stds[i]))
# plot the means and standard deviations
plt.figure(figsize=(14,5))
plt.subplot(121)
plt.plot(Hs.keys(), layer_means, 'ob-')
plt.title('layer mean')
plt.subplot(122)
plt.plot(Hs.keys(),layer_stds, 'or-')
plt.title('layer std')
# plot the raw distributions
plt.figure(figsize=(15,5))
for i,H in Hs.items():
plt.subplot(1, len(Hs), i+1)
plt.hist(H.ravel(), 50, range=(-1,1))
500개의 뉴런을 가진 layer가 10개 있으며 초기값을 0으로 설정해주었다. 먼저 각 layer의 평균과 표준편차를 구하면 다음과 같다.
뒤쪽 layer로 갈수록 표준편차가 점점 작아지다가 결국 평균과 표준편차가 모두 0이 되어버린다. 모든 activation이 0이 되어버렸으므로, vanishing gradient 현상이 발생한다. 이러한 초기화 방법은 데이터의 size가 작거나 적은 layer를 사용하면 큰 문제가 없지만, 지금처럼 데이터의 양이 조금만 많아져도 모든 뉴런이 같은 역할을 하게 되어버린다. 굳이 여러 layer를 쌓을 필요가 없는 것이다.
이번에는 표준편차를 크게 했을 때 어떤 변화가 있을지 알아보자. 아래의 초기화 부분을 제외하면 위의 코드와 동일하다.
W = np.random.randn(fan_in, fan_out)*1.0
앞선 케이스와는 정반대의 양상을 보여준다. 표준편차가 너무 커서 대부분의 뉴런이 -1과 1의 값만을 가지게 되는 saturation 현상이 발생하고 모든 gradient가 0이 되어버린다.
Reasonable Initialization
결국 우리는 layer를 늘리더라도 saturation되지 않는 범위 내에서 layer의 평균과 표준편차를 일정하게 유지하기를 원한다. 이러한 결과를 얻기 위한 방안으로 분산 조정 기반 초기화 방법이 제시되었다.
Xavier Initialization
Xavier initialization은 입력값과 출력값의 차원을 고려하여 분산을 결정하는 초기화 방법으로 모든 layer마다 분산을 다르게 적용할 수 있다. 구체적인 수식은 다음과 같다. 입력값과 출력값의 차원이 같다면 오른쪽 수식처럼 간단해진다.
\[Var(W) = \frac{2}{n_{in} + n_{out}} \text{ or } \frac{1}{n_{in}}\]W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in) # assume same sizes
실험 결과 뒤쪽 layer에서도 activation이 고르게 분포되어 있음을 알 수 있다. 하지만 Xavier initialization이 만능은 아니다. ReLU 활성함수를 사용하면 음의 값은 전부 0으로 출력되기 때문에 앞선 케이스와 비슷한 좋지 않은 결과가 발생한다.
He Initialization
Xavier initialization의 문제점을 보완하기 위해 제시된 방안으로 He initialization이 있다. 이는 입력값의 차원만을 고려한 것으로서 주로 ReLU 활성함수를 사용할 때 함께 사용한다.
\[Var(W) = \frac{2}{n_{in}}\]W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in/2) # assume same sizes
activation이 다시 고르게 분포되어 있음을 확인할 수 있다. 요약하자면 ReLU 계열은 He 초기화를, 나머지는 Xavier 초기화를 사용하면 된다. 이 분야는 지금도 활발하게 연구되고 있기 때문에 최신 동향을 살펴가며 알맞은 초기화 기법을 사용하면 좋을 것 같다.