
[CS231n]Lecture 4-Backpropagation and Neural Networks
02 Mar 2020 | CS231n
Lecture 4-Backpropagation and Neural Networks와 강의자료를 참고하여 개인적으로 정리한 글입니다.
지난 글에서 다룬 loss function(손실 함수)과 optimization(최적화)에 대해 간단히 요약해보자.
- 이미지를 잘 분류하는 분류기를 만들기 위해 현재 얼마나 잘못 분류했는지에 대한 척도가 필요하며 그것이 손실 함수의 역할이다.
- 손실 함수로는 Hinge loss, Cross Entropy, MSE 등이 있다.
- 우리의 목표는 손실 함수를 최소화하는 것이며 그 과정을 최적화라고 한다.
- 최적화 방법으로는 GD, SGD, MGD, Adam 등이 있다.
이번 글에서는 최적화 과정의 일부인 $\nabla L_W$를 구하는 방법에 대해 알아보려고 한다.
Backpropagation
Gradient descent 과정 중 다음 과정을 자세히 살펴보자.
초깃값 $W_0$와 training data를 이용해 loss를 구하고 gradient($\nabla L_W$)를 계산해서 loss가 최소가 되는 방향을 찾는다.
초깃값과 학습 데이터로 loss를 구하는 과정까진 좋은데 그 다음이 문제다. $\nabla L_W$를 계산하려면 손실함수 $L(W)$를 모든 차원에 대해 편미분한 후 값을 대입해야 하는데, 딥러닝에서는 차원이 조금 높은 수준이 아니다. 차원이 많은 것을 감수하고 직접 계산한다고 해도 그 과정은 굉장히 괴로워 보인다. 그래서 우리는 직접 미분하지 않고 computational graph를 이용해 gradient 값만 구할 것이고 이를 backpropagation(역전파)이라고 한다.
참고 : Gradient
Computational Graph
Backpropagation을 이해하기 위해 computational graph를 먼저 알아야 한다. 예시를 통해 알아보자. 함수 $f(x,y,z)=(x+y)z$를 computational graph로 표현하면 다음과 같다.
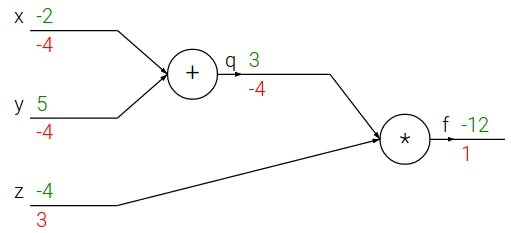
함수 내의 모든 연산을 쪼개서 node를 구성하고 각각을 연결해주면 된다. Computational graph의 장점은 전체와 상관없이 해당 node에 관련된 값으로 하나의 연산만 하면 되고, 중간 계산 값을 모두 기억할 수 있다는 점이다. 또한 역전파를 통해 미분값을 쉽게 구할 수 있다.
Backpropagation(Scalar)
위의 그래프에서 초록색의 숫자는 forward propagation(순전파)에서의 값이고, 빨간색 숫자는 각 변수에 대한 미분값이다. 어떻게 계산되었는지 알아보자.
순전파 과정은 단순한 계산이다. $x=-2$와 $y=5$를 더하고 $z=-4$와 곱하여 결과값인 -12를 얻는다. 순전파가 완료되면 역전파로 넘어가는데, 용어에서도 알 수 있듯 순전파와 정반대방향으로 진행된다. 우선 우리가 최종적으로 계산해야할 값은 $\nabla f=(\frac{\partial f }{\partial x}, \frac{\partial f }{\partial y}, \frac{\partial f }{\partial z})$ 임을 기억하자.
가장 끝에서부터 미분값을 계산하면 $\frac{\partial f}{\partial f} = 1$이다. 처음 미분값은 당연히 항상 1이다. 그 다음 중간 값인 $q=x+y$의 미분값을 구하면 $\frac{\partial f}{\partial q} = z$이므로 그 값은 -4이다. 비슷하게 $\frac{\partial f}{\partial z} = q$ 이므로 그 값은 3이다.
$\frac{\partial f}{\partial x}$와 $\frac{\partial f}{\partial y}$는 바로 구할 수 없기 때문에 chain rule을 이용한다. $\frac{\partial f}{\partial x} = \frac{\partial f}{\partial q} \frac{\partial q}{\partial x}$ 이고 $\frac{\partial f}{\partial q}$는 이미 구했기 때문에 $\frac{\partial q}{\partial x}$만 계산하면 된다. $q=x+y$이므로 $\frac{\partial q}{\partial x}=1$이다. 따라서 $\frac{\partial f}{\partial x}=-4$가 된다. 비슷하게 $\frac{\partial f}{\partial y}=-4$임을 알 수 있다. 여기서 $\frac{\partial f}{\partial q}$처럼 미리 계산한 미분값을 upstream gradient라고 하고, $\frac{\partial q}{\partial x}$를 그 node의 local gradient라고 한다. 결국 역전파는 입력값에 다다를 때까지 chain rule을 이용해서 local gradient와 upstream gradient를 계속 곱해나가는 과정이라고 할 수 있다. 이는 우리 생각보다 훨씬 효율적이고 빠르다. 다음 예시로 직접 연습해보면 좋을 것 같다.
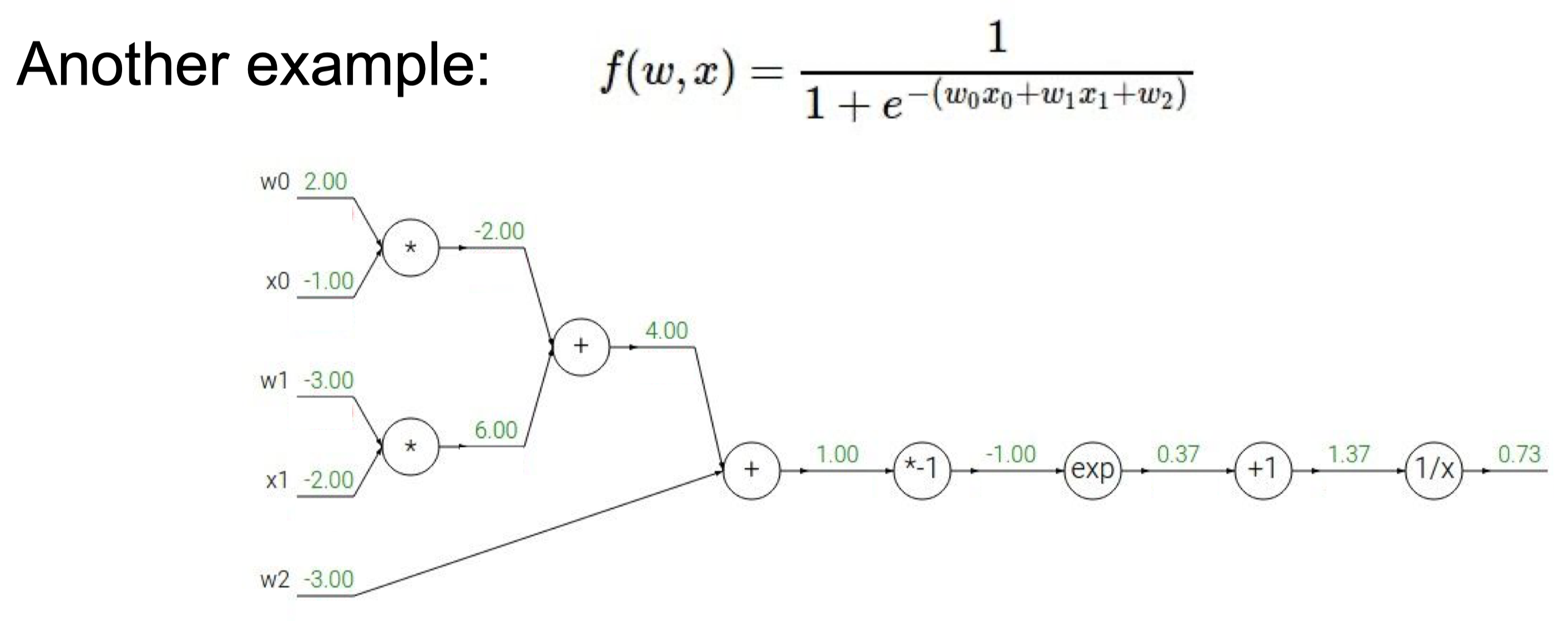
정답 : 강의자료 43p.
Patterns in Backward Flow
함수 $f(x,y,z,w)=2(xy + max(z,w))$를 computational graph로 표현하면 아래와 같다. 이를 통해 자주 등장하는 연산인 $+, \cdot, max$ 및 상수배는 gradient를 어떻게 전달하는지 살펴보자.
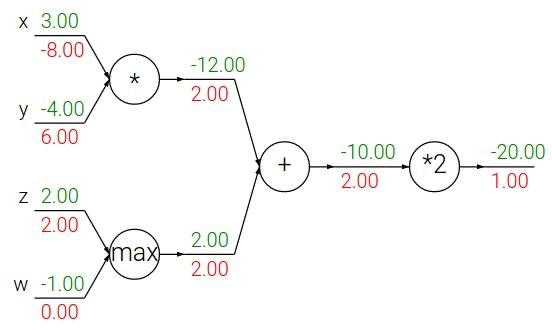
$\alpha = xy, \beta=max(z,w),\gamma=\alpha+\beta$라고 하자.
-
Constant multiplication gate
먼저 $\frac{\partial f}{\partial \gamma}$를 구할텐데 $f=2\gamma$이므로 $\frac{\partial f}{\partial \gamma}=2$이다. 즉, 상수배는 upstream gradient를 해당 상수만큼 곱해서 전달한다.
-
Addition gate(Gradient distributor)
$\frac{\partial f}{\partial \alpha} = \frac{\partial f}{\partial \gamma} \frac{\partial \gamma}{\partial \alpha}$ 이고, $\gamma = \alpha + \beta$이므로 $\frac{\partial f}{\partial \alpha} = 2 * 1 = 2$이다. 마찬가지로 $\frac{\partial f}{\partial \beta} = 2$이다. 즉, 덧셈 연산은 local gradient가 1이므로 upstream gradient를 그대로 전달한다.
-
Multiplication gate(Gradient switcher)
$\alpha = xy$이므로 $\frac{\partial \alpha}{\partial x} = y = -4$이다. 따라서 $\frac{\partial f}{\partial x} = 2 * (-4) = -8$이다. 비슷하게 $\frac{\partial f}{\partial y} = 2 * 3 = 6$이다. 이처럼 곱셈 연산은 local gradient와 두 변수의 값을 바꿔 곱해 전달한다.
-
Max gate(Gradient router)
$max$연산은 큰 값에만 gradient를 전달하고, 작은 값에는 0을 전달한다.
Backpropagation(Vector)
사실 위의 예시처럼 실제 계산에서는 입력값과 $W$가 모두 벡터다. 하지만 미분의 결과가 하나의 값이 아니라 jacobian matrix라는 것 외에는 차이가 없다.
참고 : 강의자료 74p.
Neural Networks
지금부터는 neural networks에 대해 이야기하려고 한다. 단순한 선형 분류기(linear classifier)와 어떤 차이가 있길래 neural networks를 사용하는걸까?
Neural Networks
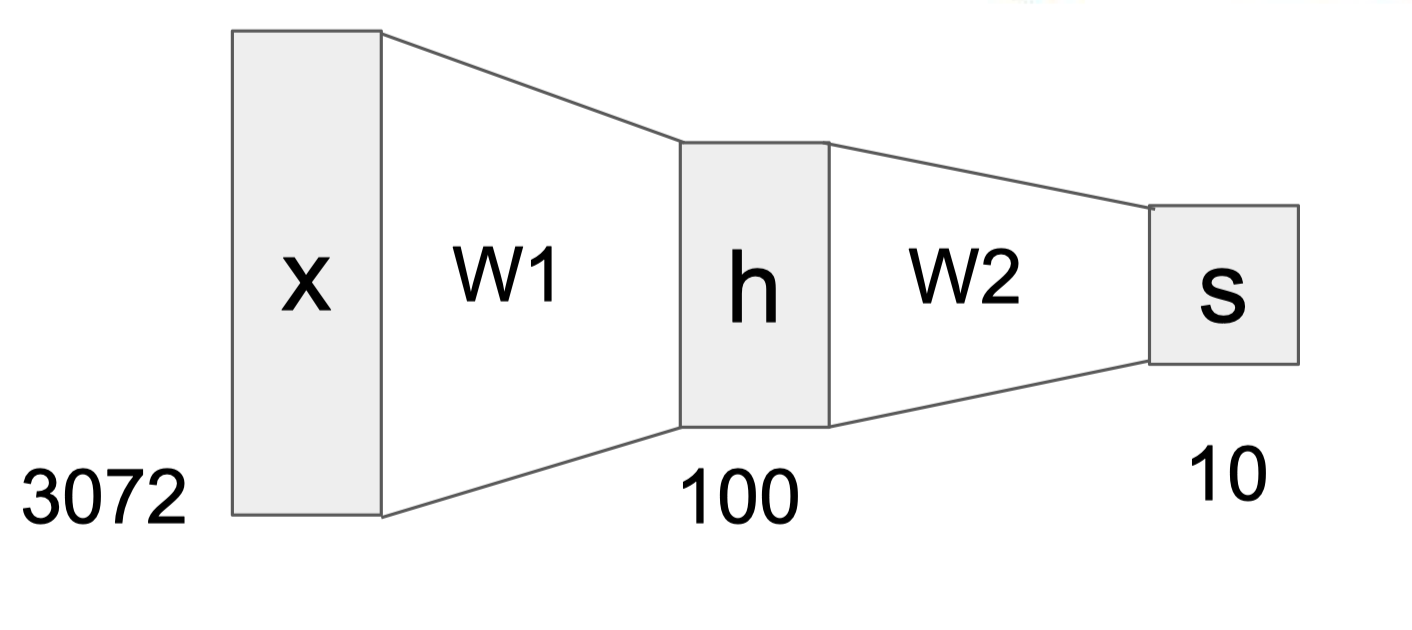
-
Linear score function : $f_1 = Wx$
-
2-Layer Neural Network : $f_2 = W_2 max(0,W_1x)$
-
3-Layer Neural Network : $f_3 = W_3 max(0, W_2 max(0, W_1x))$
위의 식과 같이 2-Layer neural network를 만들고 싶다면 선형 분류기의 결과값을 비선형 함수(non-linear function)에 대입한 후 다시 weight와 곱해주면 된다. 이 경우 비선형 함수로 ReLu가 사용되었다. 신경망 구조에서는 이러한 비선형 함수를 activation function(활성 함수)이라고 한다. Activation function은 6강에서 자세히 다루겠지만, 간단히 이야기하자면 이전의 직선(혹은 hyperplane)과 같은 선형 경계를 복잡하게 꺾어주는 것이라고 생각하면 된다. 즉, 신경망 구조는 비선형 경계를 통해 분류함으로써 정확도를 높일 수 있다.
또한 신경망 구조에서 각각의 $W_i$들은 일종의 template이라고 생각할 수 있는데, 여러 template을 겹겹이 쌓음으로써 template들을 조합하는 효과를 얻는다. 예를 들어, 선형 분류기가 빨간색 자동차의 정면 사진만을 자동차로 분류했다면 신경망 구조는 노란색 측면 사진 또한 자동차로 분류할 수 있는 것처럼 말이다. 중간의 hidden layer $h$는 입력값 $x$와 첫번째 template $W_1$가 곱해진 값으로 $h$ 속 100개의 node는 $W_1$이 가지고 있는 100개의 template들이 입력값에 얼마나 존재하는지에 대한 정보를 지닌다. 여기에 $W_2$를 곱하면 $h$의 값들을 조합하면서 하나의 label에 대해 다양한 template을 대응시킬 수 있다.
Analogy of Neural Networks
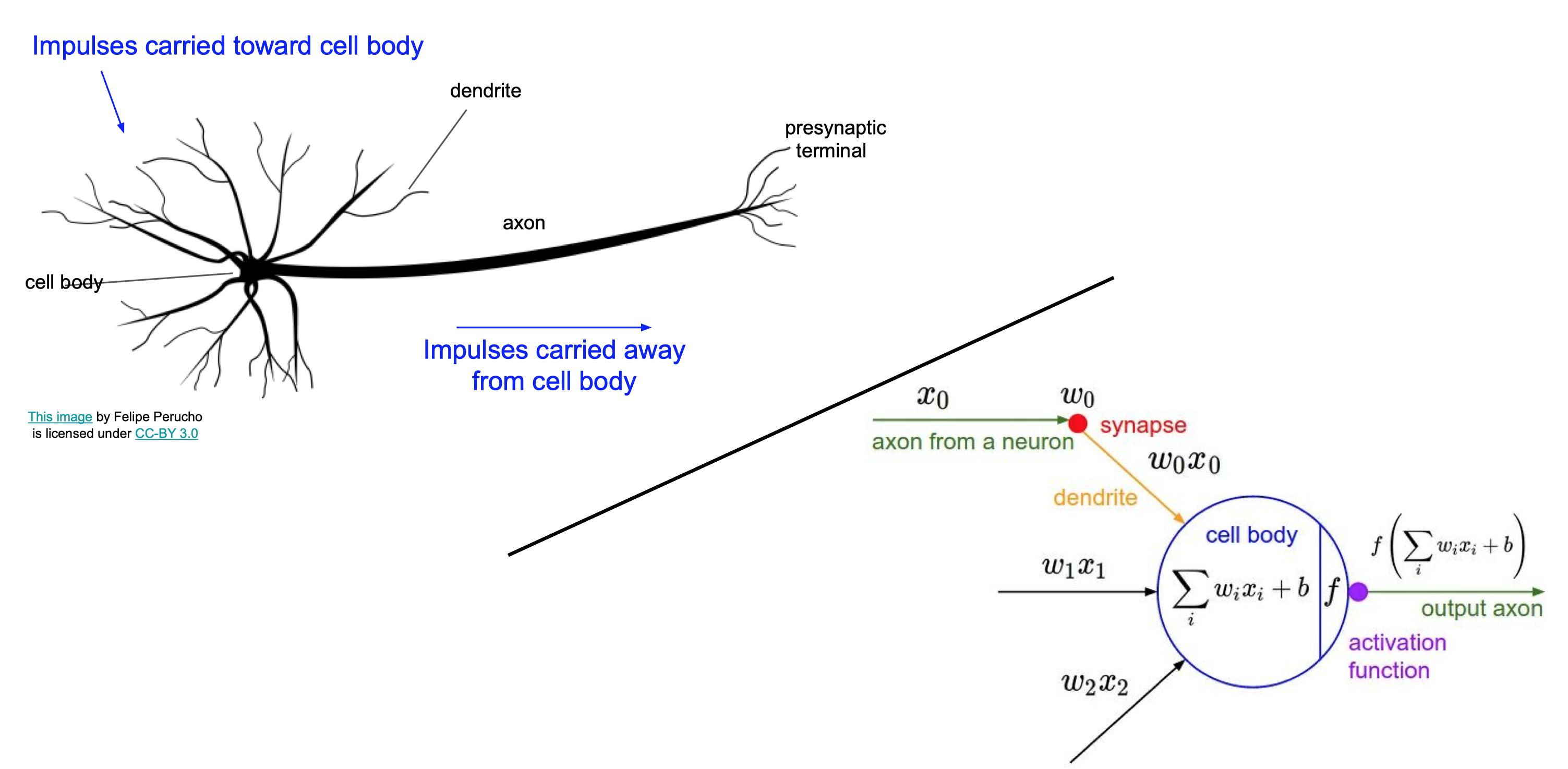
Neural networks의 이름에 대해서 살펴보자. 대략적인 신경 자극 전달 과정은 앞 신경으로부터 자극을 받고 그것들을 종합한 뒤 일정 자극을 넘어서면 다음 신경으로 전달하는 방식이다. 전달받은 자극의 강도에 따라 다음 신경으로 전달하는 자극의 세기가 달라질 수 있다. $W$를 곱하고 activation function을 거치면서 다음 layer로 전달될 값이 결정되는 과정이 신경 자극 전달 과정과 비슷하다 하여 neural networks라는 이름을 가지게 된 것이다. 하지만 실제 생물학적 신경은 매우 복잡하고 기능도 다양하기 때문에 완전히 동일한 방식이라고 생각하면 안 된다. 단지 방식이 비슷한 것에 영감(loose inspiration)을 받아 이름을 지은 것 같다.
Fully-Connected Layers
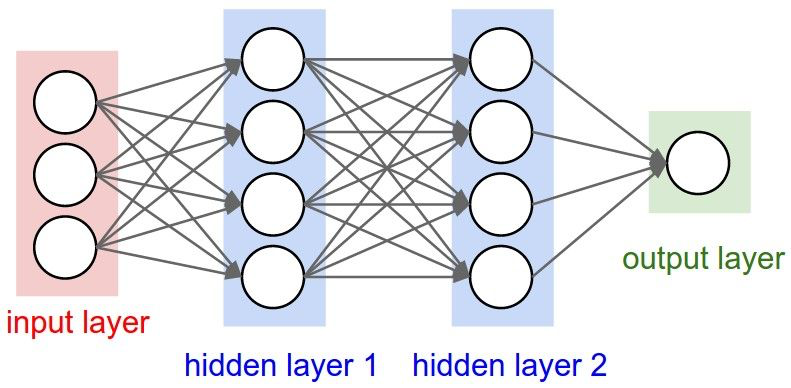
위의 그림처럼 입력층을 제외한 모든 layer의 모든 node가 전부 연결되어 있으면 fully-connected layers(FC)라고 한다. 또한 층의 갯수를 셀 때 입력층은 포함시키지 않는다.
Lecture 4-Backpropagation and Neural Networks와 강의자료를 참고하여 개인적으로 정리한 글입니다.
지난 글에서 다룬 loss function(손실 함수)과 optimization(최적화)에 대해 간단히 요약해보자.
- 이미지를 잘 분류하는 분류기를 만들기 위해 현재 얼마나 잘못 분류했는지에 대한 척도가 필요하며 그것이 손실 함수의 역할이다.
- 손실 함수로는 Hinge loss, Cross Entropy, MSE 등이 있다.
- 우리의 목표는 손실 함수를 최소화하는 것이며 그 과정을 최적화라고 한다.
- 최적화 방법으로는 GD, SGD, MGD, Adam 등이 있다.
이번 글에서는 최적화 과정의 일부인 $\nabla L_W$를 구하는 방법에 대해 알아보려고 한다.
Backpropagation
Gradient descent 과정 중 다음 과정을 자세히 살펴보자.
초깃값 $W_0$와 training data를 이용해 loss를 구하고 gradient($\nabla L_W$)를 계산해서 loss가 최소가 되는 방향을 찾는다.
초깃값과 학습 데이터로 loss를 구하는 과정까진 좋은데 그 다음이 문제다. $\nabla L_W$를 계산하려면 손실함수 $L(W)$를 모든 차원에 대해 편미분한 후 값을 대입해야 하는데, 딥러닝에서는 차원이 조금 높은 수준이 아니다. 차원이 많은 것을 감수하고 직접 계산한다고 해도 그 과정은 굉장히 괴로워 보인다. 그래서 우리는 직접 미분하지 않고 computational graph를 이용해 gradient 값만 구할 것이고 이를 backpropagation(역전파)이라고 한다.
참고 : Gradient
Computational Graph
Backpropagation을 이해하기 위해 computational graph를 먼저 알아야 한다. 예시를 통해 알아보자. 함수 $f(x,y,z)=(x+y)z$를 computational graph로 표현하면 다음과 같다.
함수 내의 모든 연산을 쪼개서 node를 구성하고 각각을 연결해주면 된다. Computational graph의 장점은 전체와 상관없이 해당 node에 관련된 값으로 하나의 연산만 하면 되고, 중간 계산 값을 모두 기억할 수 있다는 점이다. 또한 역전파를 통해 미분값을 쉽게 구할 수 있다.
Backpropagation(Scalar)
위의 그래프에서 초록색의 숫자는 forward propagation(순전파)에서의 값이고, 빨간색 숫자는 각 변수에 대한 미분값이다. 어떻게 계산되었는지 알아보자.
순전파 과정은 단순한 계산이다. $x=-2$와 $y=5$를 더하고 $z=-4$와 곱하여 결과값인 -12를 얻는다. 순전파가 완료되면 역전파로 넘어가는데, 용어에서도 알 수 있듯 순전파와 정반대방향으로 진행된다. 우선 우리가 최종적으로 계산해야할 값은 $\nabla f=(\frac{\partial f }{\partial x}, \frac{\partial f }{\partial y}, \frac{\partial f }{\partial z})$ 임을 기억하자.
가장 끝에서부터 미분값을 계산하면 $\frac{\partial f}{\partial f} = 1$이다. 처음 미분값은 당연히 항상 1이다. 그 다음 중간 값인 $q=x+y$의 미분값을 구하면 $\frac{\partial f}{\partial q} = z$이므로 그 값은 -4이다. 비슷하게 $\frac{\partial f}{\partial z} = q$ 이므로 그 값은 3이다.
$\frac{\partial f}{\partial x}$와 $\frac{\partial f}{\partial y}$는 바로 구할 수 없기 때문에 chain rule을 이용한다. $\frac{\partial f}{\partial x} = \frac{\partial f}{\partial q} \frac{\partial q}{\partial x}$ 이고 $\frac{\partial f}{\partial q}$는 이미 구했기 때문에 $\frac{\partial q}{\partial x}$만 계산하면 된다. $q=x+y$이므로 $\frac{\partial q}{\partial x}=1$이다. 따라서 $\frac{\partial f}{\partial x}=-4$가 된다. 비슷하게 $\frac{\partial f}{\partial y}=-4$임을 알 수 있다. 여기서 $\frac{\partial f}{\partial q}$처럼 미리 계산한 미분값을 upstream gradient라고 하고, $\frac{\partial q}{\partial x}$를 그 node의 local gradient라고 한다. 결국 역전파는 입력값에 다다를 때까지 chain rule을 이용해서 local gradient와 upstream gradient를 계속 곱해나가는 과정이라고 할 수 있다. 이는 우리 생각보다 훨씬 효율적이고 빠르다. 다음 예시로 직접 연습해보면 좋을 것 같다.
정답 : 강의자료 43p.
Patterns in Backward Flow
함수 $f(x,y,z,w)=2(xy + max(z,w))$를 computational graph로 표현하면 아래와 같다. 이를 통해 자주 등장하는 연산인 $+, \cdot, max$ 및 상수배는 gradient를 어떻게 전달하는지 살펴보자.
$\alpha = xy, \beta=max(z,w),\gamma=\alpha+\beta$라고 하자.
-
Constant multiplication gate
먼저 $\frac{\partial f}{\partial \gamma}$를 구할텐데 $f=2\gamma$이므로 $\frac{\partial f}{\partial \gamma}=2$이다. 즉, 상수배는 upstream gradient를 해당 상수만큼 곱해서 전달한다.
-
Addition gate(Gradient distributor)
$\frac{\partial f}{\partial \alpha} = \frac{\partial f}{\partial \gamma} \frac{\partial \gamma}{\partial \alpha}$ 이고, $\gamma = \alpha + \beta$이므로 $\frac{\partial f}{\partial \alpha} = 2 * 1 = 2$이다. 마찬가지로 $\frac{\partial f}{\partial \beta} = 2$이다. 즉, 덧셈 연산은 local gradient가 1이므로 upstream gradient를 그대로 전달한다.
-
Multiplication gate(Gradient switcher)
$\alpha = xy$이므로 $\frac{\partial \alpha}{\partial x} = y = -4$이다. 따라서 $\frac{\partial f}{\partial x} = 2 * (-4) = -8$이다. 비슷하게 $\frac{\partial f}{\partial y} = 2 * 3 = 6$이다. 이처럼 곱셈 연산은 local gradient와 두 변수의 값을 바꿔 곱해 전달한다.
-
Max gate(Gradient router)
$max$연산은 큰 값에만 gradient를 전달하고, 작은 값에는 0을 전달한다.
Backpropagation(Vector)
사실 위의 예시처럼 실제 계산에서는 입력값과 $W$가 모두 벡터다. 하지만 미분의 결과가 하나의 값이 아니라 jacobian matrix라는 것 외에는 차이가 없다.
참고 : 강의자료 74p.
Neural Networks
지금부터는 neural networks에 대해 이야기하려고 한다. 단순한 선형 분류기(linear classifier)와 어떤 차이가 있길래 neural networks를 사용하는걸까?
Neural Networks
-
Linear score function : $f_1 = Wx$
-
2-Layer Neural Network : $f_2 = W_2 max(0,W_1x)$
-
3-Layer Neural Network : $f_3 = W_3 max(0, W_2 max(0, W_1x))$
위의 식과 같이 2-Layer neural network를 만들고 싶다면 선형 분류기의 결과값을 비선형 함수(non-linear function)에 대입한 후 다시 weight와 곱해주면 된다. 이 경우 비선형 함수로 ReLu가 사용되었다. 신경망 구조에서는 이러한 비선형 함수를 activation function(활성 함수)이라고 한다. Activation function은 6강에서 자세히 다루겠지만, 간단히 이야기하자면 이전의 직선(혹은 hyperplane)과 같은 선형 경계를 복잡하게 꺾어주는 것이라고 생각하면 된다. 즉, 신경망 구조는 비선형 경계를 통해 분류함으로써 정확도를 높일 수 있다.
또한 신경망 구조에서 각각의 $W_i$들은 일종의 template이라고 생각할 수 있는데, 여러 template을 겹겹이 쌓음으로써 template들을 조합하는 효과를 얻는다. 예를 들어, 선형 분류기가 빨간색 자동차의 정면 사진만을 자동차로 분류했다면 신경망 구조는 노란색 측면 사진 또한 자동차로 분류할 수 있는 것처럼 말이다. 중간의 hidden layer $h$는 입력값 $x$와 첫번째 template $W_1$가 곱해진 값으로 $h$ 속 100개의 node는 $W_1$이 가지고 있는 100개의 template들이 입력값에 얼마나 존재하는지에 대한 정보를 지닌다. 여기에 $W_2$를 곱하면 $h$의 값들을 조합하면서 하나의 label에 대해 다양한 template을 대응시킬 수 있다.
Analogy of Neural Networks
Neural networks의 이름에 대해서 살펴보자. 대략적인 신경 자극 전달 과정은 앞 신경으로부터 자극을 받고 그것들을 종합한 뒤 일정 자극을 넘어서면 다음 신경으로 전달하는 방식이다. 전달받은 자극의 강도에 따라 다음 신경으로 전달하는 자극의 세기가 달라질 수 있다. $W$를 곱하고 activation function을 거치면서 다음 layer로 전달될 값이 결정되는 과정이 신경 자극 전달 과정과 비슷하다 하여 neural networks라는 이름을 가지게 된 것이다. 하지만 실제 생물학적 신경은 매우 복잡하고 기능도 다양하기 때문에 완전히 동일한 방식이라고 생각하면 안 된다. 단지 방식이 비슷한 것에 영감(loose inspiration)을 받아 이름을 지은 것 같다.
Fully-Connected Layers
위의 그림처럼 입력층을 제외한 모든 layer의 모든 node가 전부 연결되어 있으면 fully-connected layers(FC)라고 한다. 또한 층의 갯수를 셀 때 입력층은 포함시키지 않는다.